[K8S Deploy Study by Gasida] - k8s 컨트롤플레인 HA환경 구성 따라해보기 - 3 kubeadm으로 업그레이드
k8s upgrade by kubeadm
api-server파드는 3대 모두가 Active로 동작etcd는 1대가 리더역할 하며 Write처리kube-controller-manager와kube-scheduler역시 1대가 리더역할
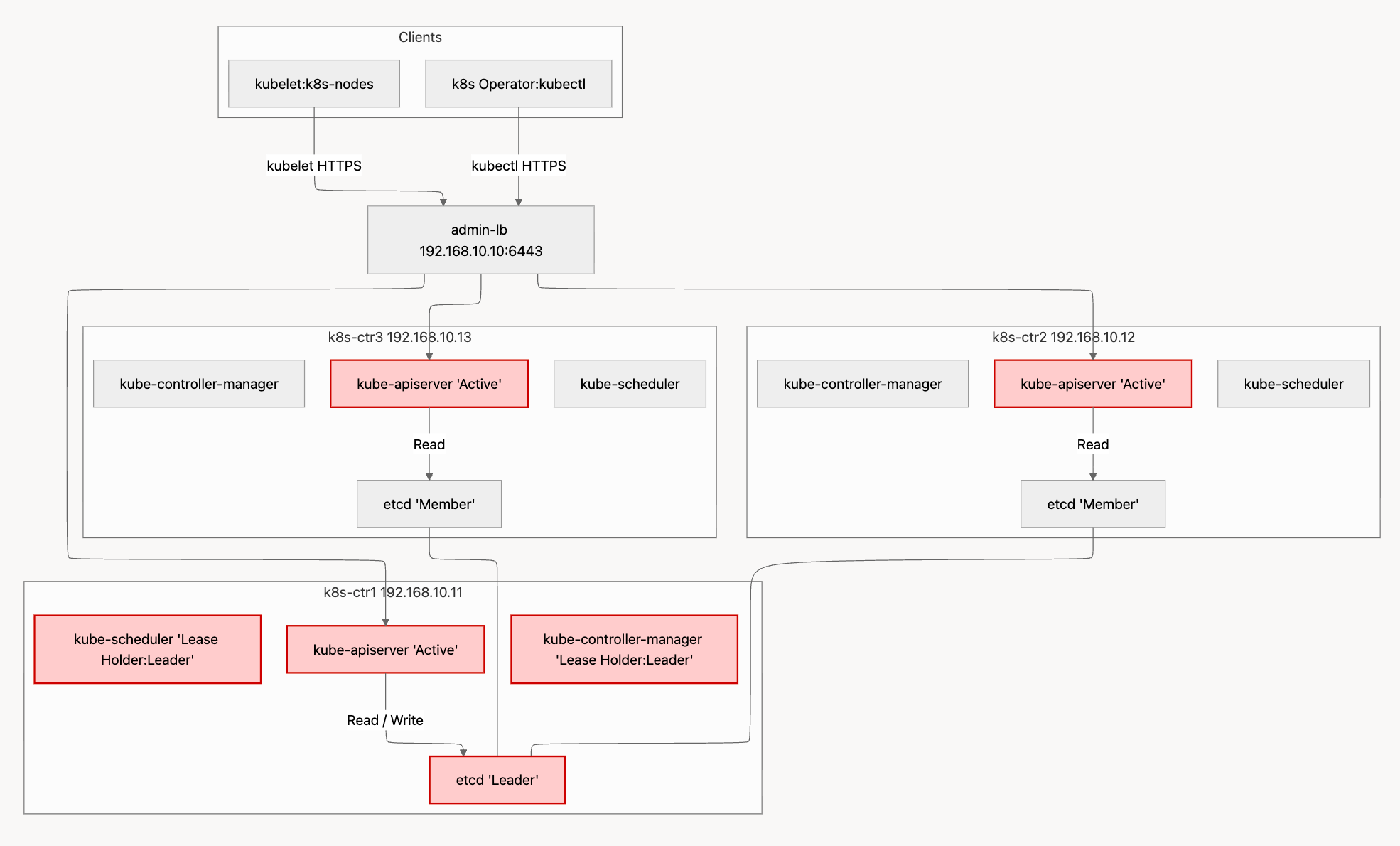
컨트롤 플레인 3대인 환경에서 1대가 장애 발생시
admin-lb(HAProxy)에 백엔드 대상k8s-ctr1이 헬스 체크 실패하니 제외하고 나머지 대상으로 요청을 전달한다.- 정상 노드 2대 중 1대의
etcd는 리더 역할이 되어, Write 처리함. (인증서 갱신과정에서 새로운리더 선출 확인) - 기존
kube-controller-manger과kube-scheduler는 리더가 k8s-ctr1 이였는데, 장애 발생 중이여서 나머지 노드에서 리더 역할을 가져감. (인증서 갱신과정에서 새로운리더 선출 확인)
결국은 1대가 장애가 발생하더라도 k8s api 호출 처리에는 문제가 없다.
사전작업
Flannel CNI 플러그인 업그레이드 : v0.27.3 → v0.27.4
- k8s-ctr1~3 노드에 미리 이미지 다운로드 해두기
기존

사전 이미지 다운로드 
- Flannel CNI 업그레이드 by helm
터미널1 : 아래 호출 중단 발생 여부 확인, IP는 node 작업에 따라 변경
1
while true; do curl -s http://192.168.10.101:30003 | grep Hostname; sleep 1; done
터미널2: kube-flannel 파드 재기동 후 정상 기동까지 시간 확인
1
watch -d kubectl get pod -n kube-flannel
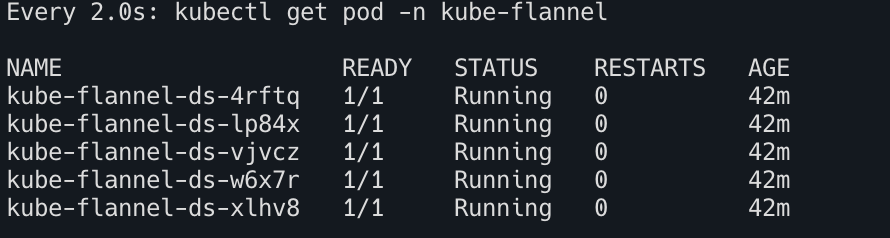
작업 전 정보 확인
1
2
3
4
helm list -n kube-flannel
helm get values -n kube-flannel flannel
kubectl get pod -n kube-flannel -o yaml | grep -i image: | sort | uniq
kubectl get ds -n kube-flannel -owide
신규버전 values 파일 작성
1
2
3
4
5
6
7
8
9
10
11
12
13
cat << EOF > flannel.yaml
podCidr: "10.244.0.0/16"
flannel:
cniBinDir: "/opt/cni/bin"
cniConfDir: "/etc/cni/net.d"
args:
- "--ip-masq"
- "--kube-subnet-mgr"
- "--iface=enp0s9"
backend: "vxlan"
image:
tag: v0.27.4
EOF
helm 업그레이드 수행 : Flannel은 DaemonSet 이므로 노드별 순차 업데이트
1
2
helm upgrade flannel flannel/flannel -n kube-flannel -f flannel.yaml --version 0.27.4
kubectl -n kube-flannel rollout status ds/kube-flannel-ds

확인
1
2
helm list -n kube-flannel
helm get values -n kube-flannel flannel

확인
1
2
3
crictl ps
kubectl get ds -n kube-flannel -owide
kubectl get pod -n kube-flannel -o yaml | grep -i image: | sort | uniq


k8s-ctr1부터 3까지 Rocky Linux 마이너 버전 Upgrade : v10.0 → v10.1 ⇒ Reboot
작업전 정보확인
vagrant ssh admin-lb
터미널1 : IP는 node 작업에 따라 변경, 아래 호출 중단 발생 확인!
1
while true; do curl -s http://192.168.10.101:30003 | grep Hostname; sleep 1; done
- 터미널2 : node 상태 확인
1
watch -d kubectl get node
vagrant ssh k8s-ctr1 진입
- 리부트전 파드정보 확인
1
2
3
4
# Rocky Linux Upgrade 후 reboot 해야되니, 미리 해당 노드에 기동되고 있는 파드 정보 확인
kubectl get pod -A -owide |grep k8s-ctr1
kubectl get pod -A -owide |grep k8s-ctr2
kubectl get pod -A -owide |grep k8s-ctr3
- Rocky Linux 버전 확인 (메이저.마이너) : 10.0
1
rpm -aq | grep release
- 커널 버전 정보 확인
1
uname -r
- (옵션) containerd.io 버전 업그레이드 되지 않게, 현재 설치 버전 고정 설정
1
rpm -q containerd.io
- 버전 잠금 플러그인 설치
1
dnf install -y 'dnf-command(versionlock)'
- containerd.io 현재 설치 버전으로 잠금
1
dnf versionlock add containerd.io
- 버전 잠금 목록 확인
1
dnf versionlock list

각 컨트롤 플레인 마이너 버전 업그레이드 수행
vagrant ssh k8s-ctr1
1
dnf -y update
- 리부트
1
2
reboot
ping 192.168.10.11
- Rocky Linux 버전 확인 (메이저.마이너) : 10.1 <- 마이너 업그레이드 확인
1
rpm -aq | grep release

- 커널 버전 정보 확인
1
uname -r

- 파드 기동 확인
1
kubectl get pod -A -owide |grep k8s-ctr
k8s-ctr2 과 k8s-ctr3도 동일작업을 진행
1
2
3
4
5
6
7
8
9
10
11
dnf install -y 'dnf-command(versionlock)'
dnf versionlock add containerd.io
dnf -y update
reboot
rpm -aq | grep release
uname -r
k8s v1.32 → v1.33 업그레이드 실습
허용되는 최대 버전 스큐에 도달할 때까지 worker 노드 업그레이드를 연기하면서 control node을 점진적으로 업그레이드
k8s-ctr1kubeadm upgrade plan/apply → kubelet/kubectl upgradek8s-ctr2kubeadm upgrade node → kubelet/kubectl upgradek8s-ctr3kubeadm upgrade node (addon upgrade) → kubelet/kubectl upgradek8s-w2node drain → kubeadm upgrade node → kubelet/kubectl upgrade → uncordonk8s-w1kubeadm upgrade node → kubelet/kubectl upgrade
k8s-ctr1 업그레이드
kubeadm 신규버전 설치
- repo 수정 : 기본 1.32 -> 1.33
1
2
3
4
5
6
7
8
9
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
1
dnf makecache
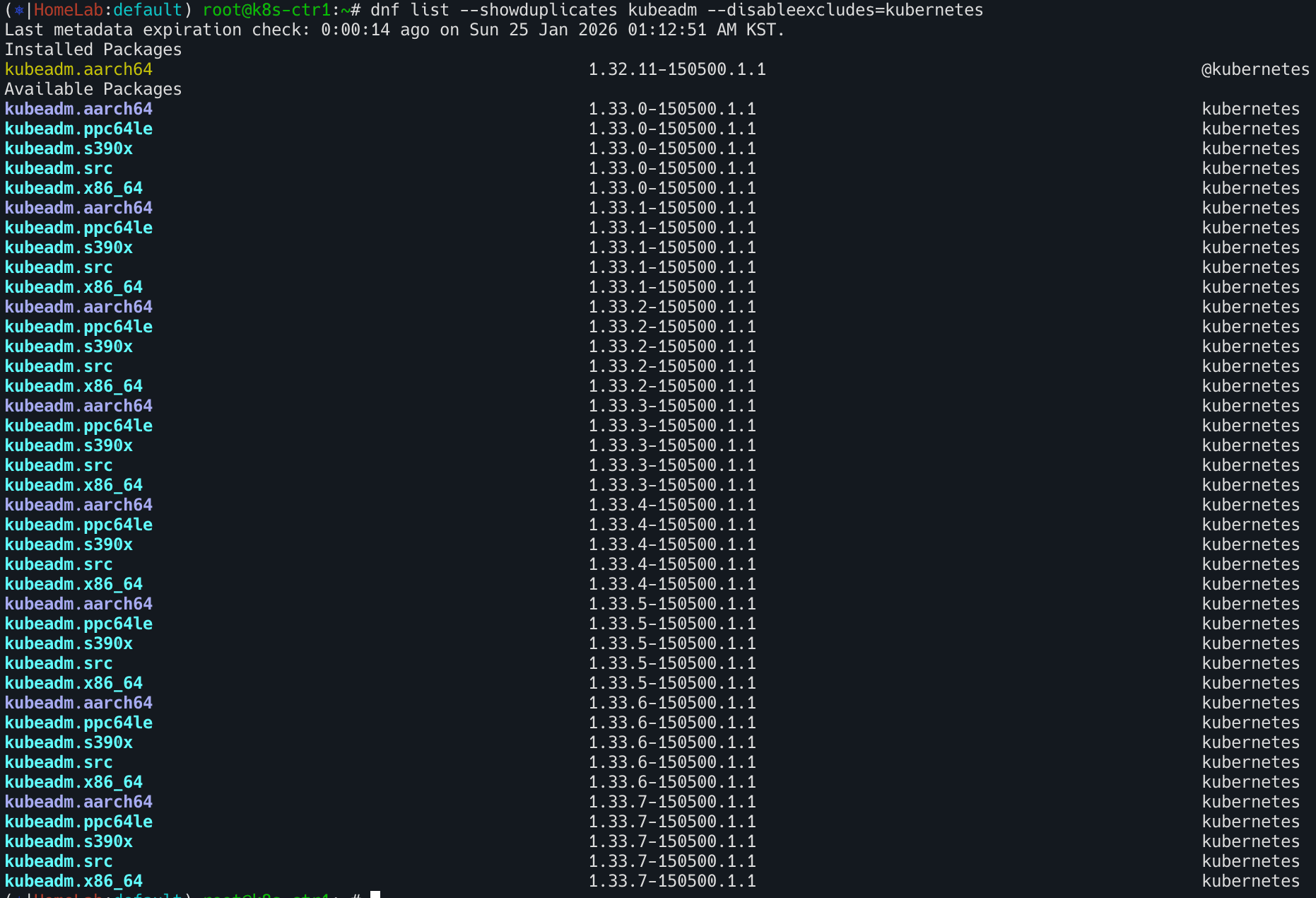
전체 설치 가능 버전 확인
--disableexcludes=...kubernetes repo에 설정된 exclude 규칙을 이번 설치에서만 무시(1회성 옵션 처럼 사용)
1
dnf list --showduplicates kubeadm --disableexcludes=kubernetes
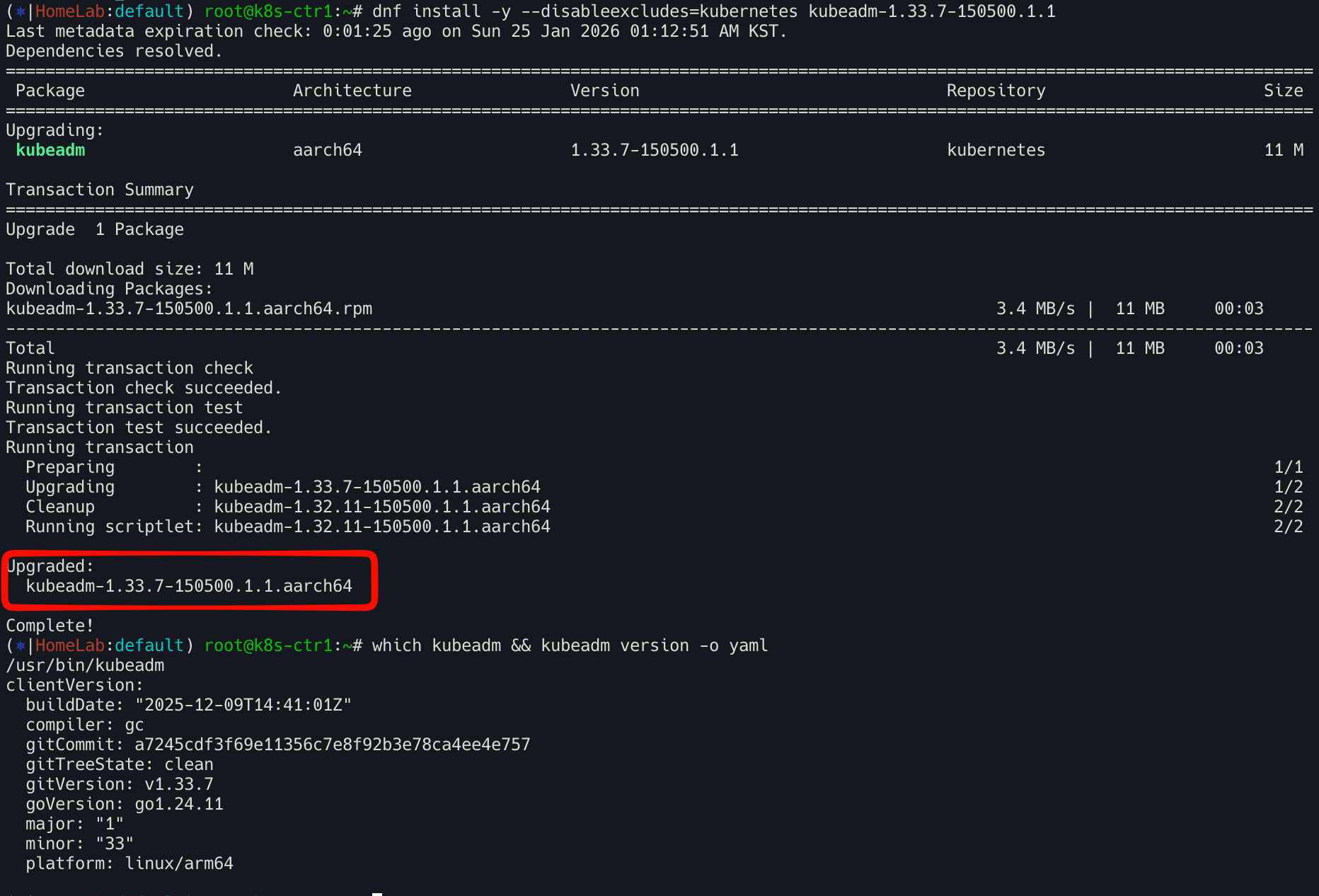
kubeadm 신규 버전 설치
1
dnf install -y --disableexcludes=kubernetes kubeadm-1.33.7-150500.1.1
설치 파일 확인
1
which kubeadm && kubeadm version -o yaml
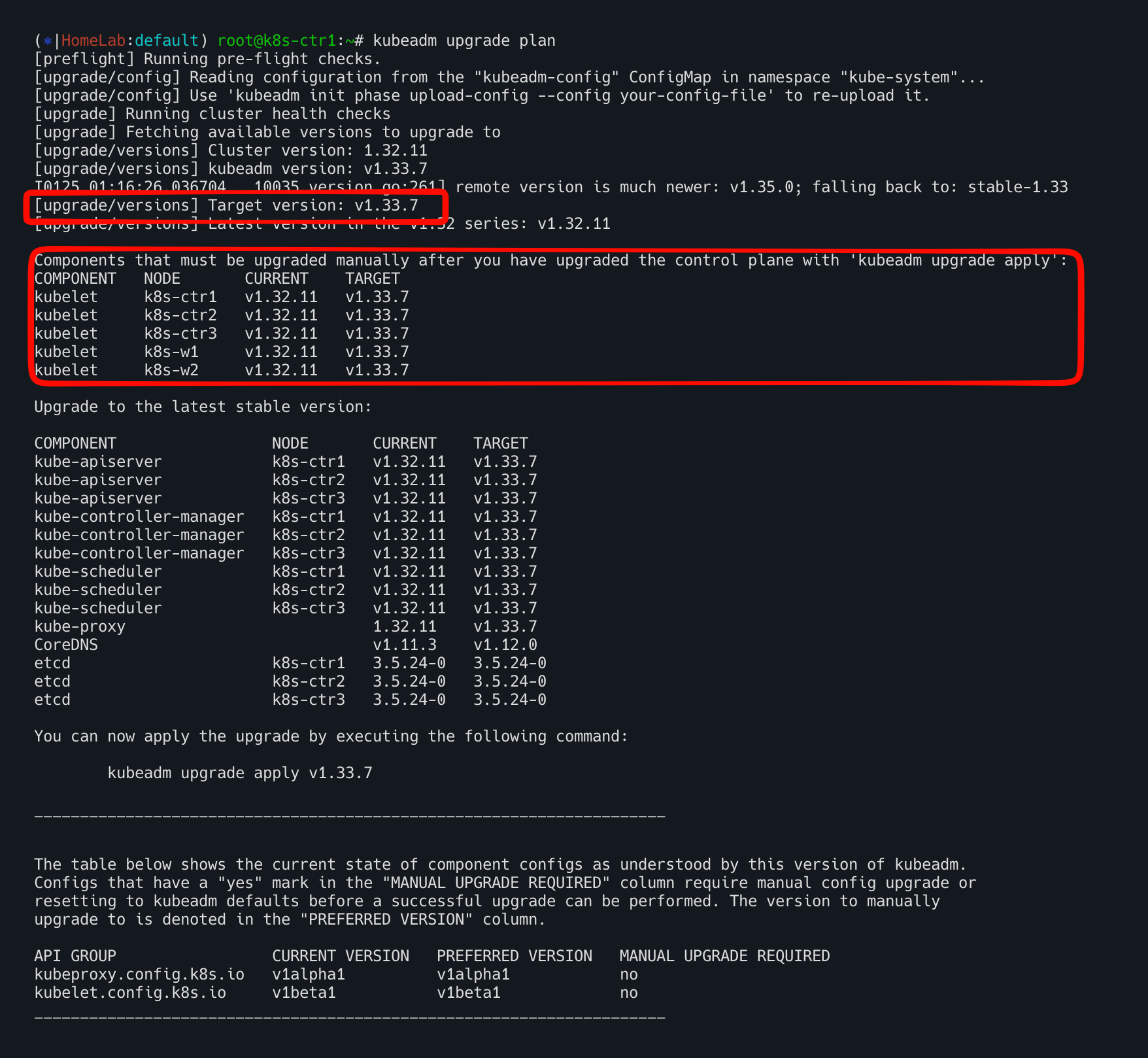
kubeadm upgrade plan 업그레이드 계획 확인
kubelet은 별도로 업그레이드 필요- 현재 작업 대상 노드에 apiserver, controller-manager, scheduler Static pod 는 신규 버전으로 재기동 예정
kube-proxy데몬셋은 신규 버전 업그레이드 예정 → (옵션) 미리 해당 이미지를 모든 노드에 다운로드 권장corednsdeployment 도 신규 버전 업그레이드 예정
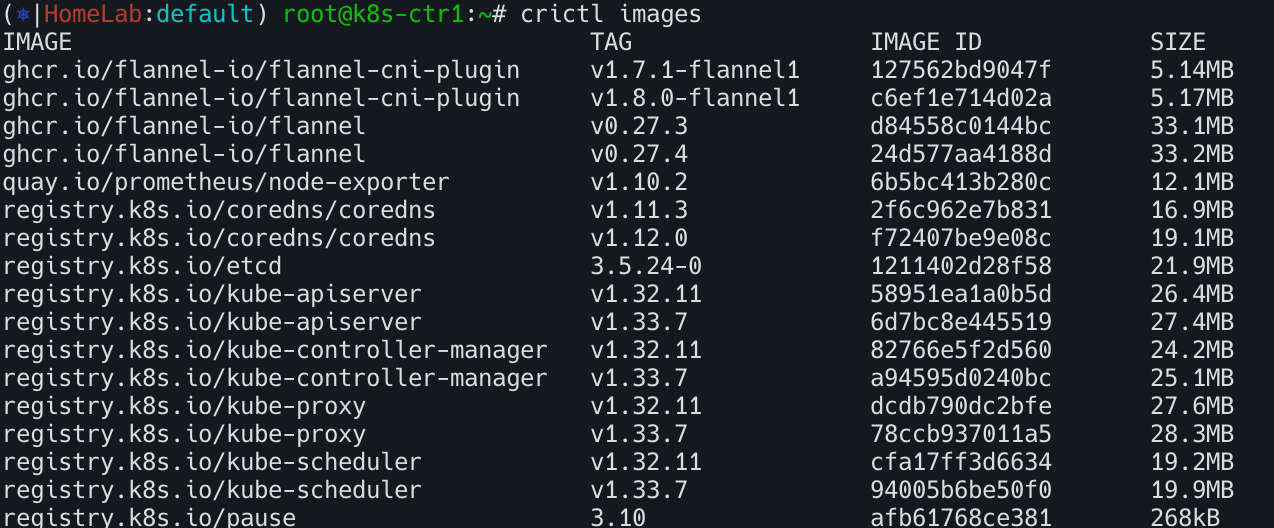
kubeadm upgrade apply 업그레이드 수행
vagrant ssh k8s-ctr1
1
2
kubeadm config images pull
crictl images

vagrant ssh k8s-w1,vagrant ssh k8s-w2
미리 해당 이미지를 모든 워커 노드에 다운로드 권장
1
crictl pull registry.k8s.io/kube-proxy:v1.33.7
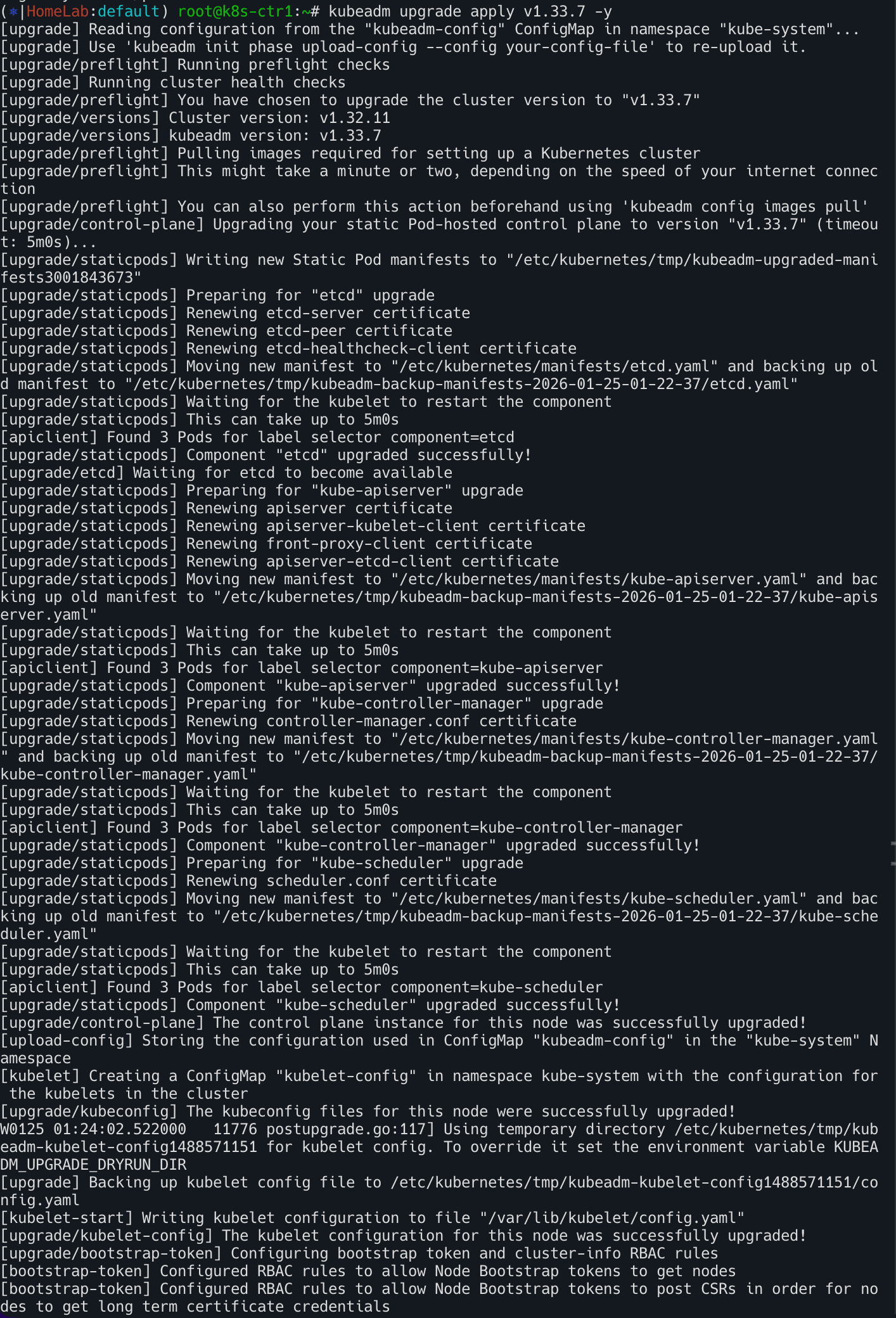
vagrant ssh k8s-ctr1- kubeadm upgrade apply 업그레이드 수행
- CA 인증서를 제외한, 나머지 인증서를 신규 생성하고, 해당 인증서를 사용하는 신규 버전의 Static Pod 를 순차적으로 기동함.
- etcd, apiserver, controller-manager, scheduler 경우 설정 변경으로 신규 파드가 생성됨.
- addon 인 kube-proxy 와 coredns 는 나머지 컨트롤 플레인 모두가 upgrade 수행 실행 시에 적용 예정으로, 현재는 Skip 됨.
1
2
3
kubeadm upgrade apply v1.33.7 -y
kubectl get ds -n kube-system -owide
kubectl get deploy -n kube-system coredns -owide


- k8s 정보 확인
1
2
3
4
# control component(apiserver, kcm 등)의 컨테이너 이미지는 1.33.7 업그레이드 되었고,
# kubelet 은 아직 업그레이드 되지 않은 상태. node 출력에 버전은 kubelet 버전을 기준 출력으로 보임.
kubectl get node -owide
kubectl describe node k8s-ctr1 | grep 'Kubelet Version:'
static pod yaml 파일 내용 업데이트 확인 : yaml 파일 내에 images 부분 업데이트
1
2
3
static pod yaml 파일 내용 업데이트 확인 : yaml 파일 내에 images 부분 업데이트
ls -l /etc/kubernetes/manifests/
cat /etc/kubernetes/manifests/*.yaml | grep -i image:
kube-system 네임스페이스 내에 동작 중인 파드 내에 컨테이너 이미지 정보 출력
1
kubectl get pods -n kube-system -o jsonpath='{range .items[*]}{.metadata.name}{"\n"}{range .spec.containers[*]} - {.name}: {.image}{"\n"}{end}{"\n"}{end}'
kubelet/kubectl 업그레이드 수행 → kubelet 재시작
설치 가능 버전확인
1
2
dnf list --showduplicates kubelet --disableexcludes=kubernetes
dnf list --showduplicates kubectl --disableexcludes=kubernetes
Upgrade 설치
1
dnf install -y --disableexcludes=kubernetes kubelet-1.33.7-150500.1.1 kubectl-1.33.7-150500.1.1
설치 파일 확인
1
2
which kubectl && kubectl version --client=true
which kubelet && kubelet --version
kubelet 재시작
- kubelet 재기동 후 정상 완료까지, 10초 정도 소요됨 -> 나머지 컨트롤플레인 노드에서 k8s api 처리됨!
1
2
systemctl daemon-reload
systemctl restart kubelet
버전 업그레이드 확인
1
2
3
kubectl get nodes -o wide
kc describe node k8s-ctr1
kubectl describe node k8s-ctr1 | grep 'Kubelet Version:'

k8s-ctr2 / k8s-ctr3 업그레이드
나머지 컨트롤 플레인도 k8s-ctr1과 동일하게 진행한다. 다만 k8s-ctr3에서 addon 업그레이드가 진행되므로 이 부분만 특별히 관찰해본다.
k8s-ctr2에서도 addon은 스키핑 된것 확인
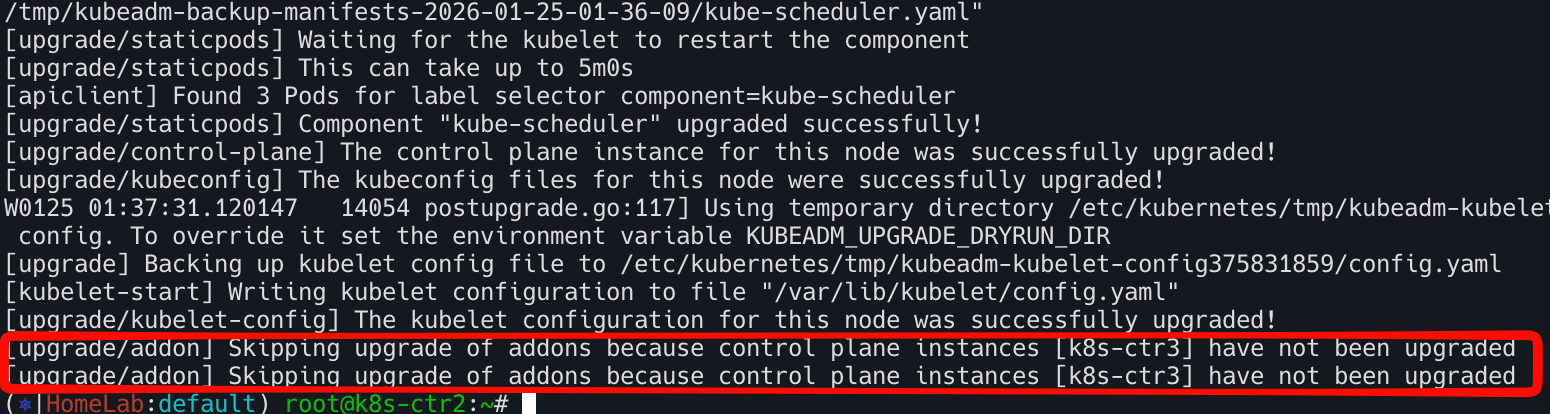
k8s-ctr3에서 addon 업그레이드 확인

- 모든 컨트롤 플레인 노드에 버전 업그레이드 확인
1
2
kubectl get nodes -o wide
kc describe node k8s-ctr3 kubectl describe node k8s-ctr3 | grep 'Kubelet Version:'

k8s-w2 node drain 후 업그레이드
(옵션) Rocky Linux Upgrade ⇒ kubeadm upgrade node → kubelet/kubectl upgrade → uncordon
작업 선택
- (방안1) Rocky Linux 업그레이드가 필요하거나, 해당 노드에 작업 시간을 가지고 해야 될 경우 : node drain 후 작업 진행
- (방안2) 해당 노드에 별도 작업 시간 계획이 어렵거나, 거의 무중단으로 작업 해야 될 경우 : drain 없이 kubelet restart 수행
node drain 수행
vagrant ssh admin-lb
모니터링
터미널1 : IP는 node 작업에 따라 변경, 아래 호출 중단 발생 확인!
1
while true; do curl -s http://192.168.10.101:30003 | grep Hostname; sleep 1; done
터미널2 : node 상태 확인
1
watch -d kubectl get node
vagrant ssh k8s-ctr1에서 해당 노드에 기동되고 있는 파드 정보 확인
1
2
kubectl get pod -A -owide | grep k8s-w1
kubectl get pod -A -owide | grep k8s-w2

drain 수행
- k8s-w2 노드가 cordoned 되고, 파드를 Evicted 하고, 최종적으로 drained 됨
- 해당 노드에 기동되고 있는 파드 정보 확인 : 데몬셋 파드 이외에 없는 것을 확인
1
2
kubectl drain k8s-w2 --ignore-daemonsets --delete-emptydir-data
kubectl get pod -A -owide | grep k8s-w2

마이너 버전 Upgrade : v10.0 → v10.1 ⇒ Reboot - 나머지 워커 노드 1대가 있으므로, 해당 노드 작업에 영향이 없음!
vagrant ssh k8s-w2
마이너 버전 Upgrade 수행 : containerd.io 도 포함.
1
dnf -y update
node Reboot! : 해당 가상머신 재부팅에 20초 정도 소요됨.
1
2
reboot
ping 192.168.10.102
Rocky Linux 버전 확인 (메이저.마이너) : 10.1 <- 마이너 업그레이드 확인
1
rpm -aq | grep release
커널 버전 정보 확인 : 6.12.0-124 <- 커널 업그레이드 확인
1
uname -r
kubeadm upgrade node → kubelet/kubectl upgrade
`` vagrant ssh k8s-w2
repo 수정 : 기본 1.32 -> 1.33
1
2
3
4
5
6
7
8
9
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
1
dnf makecache
kubeadm 설치
1
dnf install -y --disableexcludes=kubernetes kubeadm-1.33.7-150500.1.1
노드 업그레이드 수행
- kubeadm은 이 노드를 worker 노드로 판단했고, 따라서 control-plane 관련 단계는 모두 스킵하고 kubelet 설정만 업그레이드 수행!
1
kubeadm upgrade node
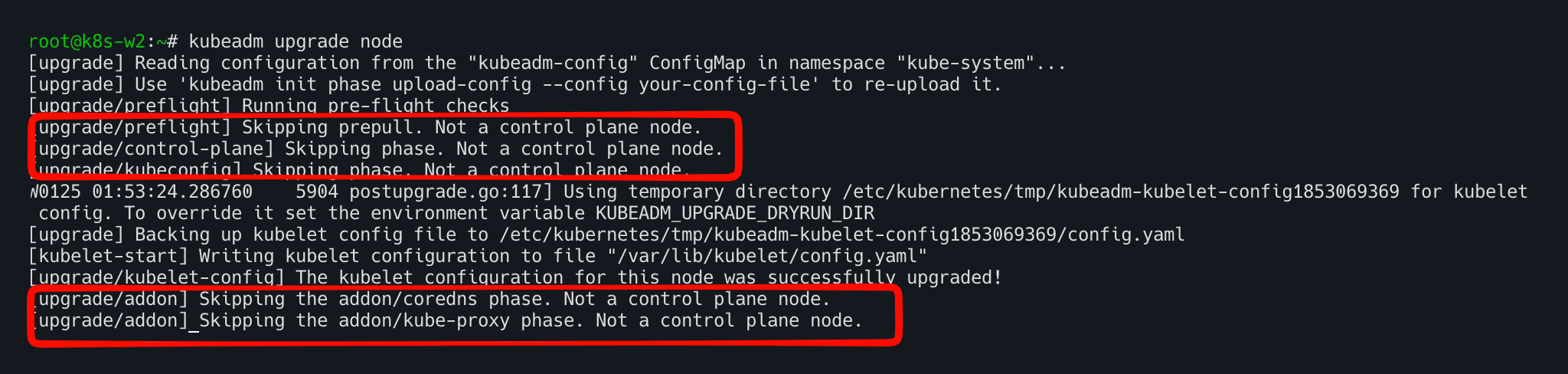
kubelet, kubectl Upgrade 설치
1
dnf install -y --disableexcludes=kubernetes kubelet-1.33.7-150500.1.1 kubectl-1.33.7-150500.1.1
재시작
1
2
3
systemctl daemon-reload
systemctl restart kubelet
systemctl status kubelet --no-pager
데몬셋 파드 정상 기동 상태 확인
1
crictl ps
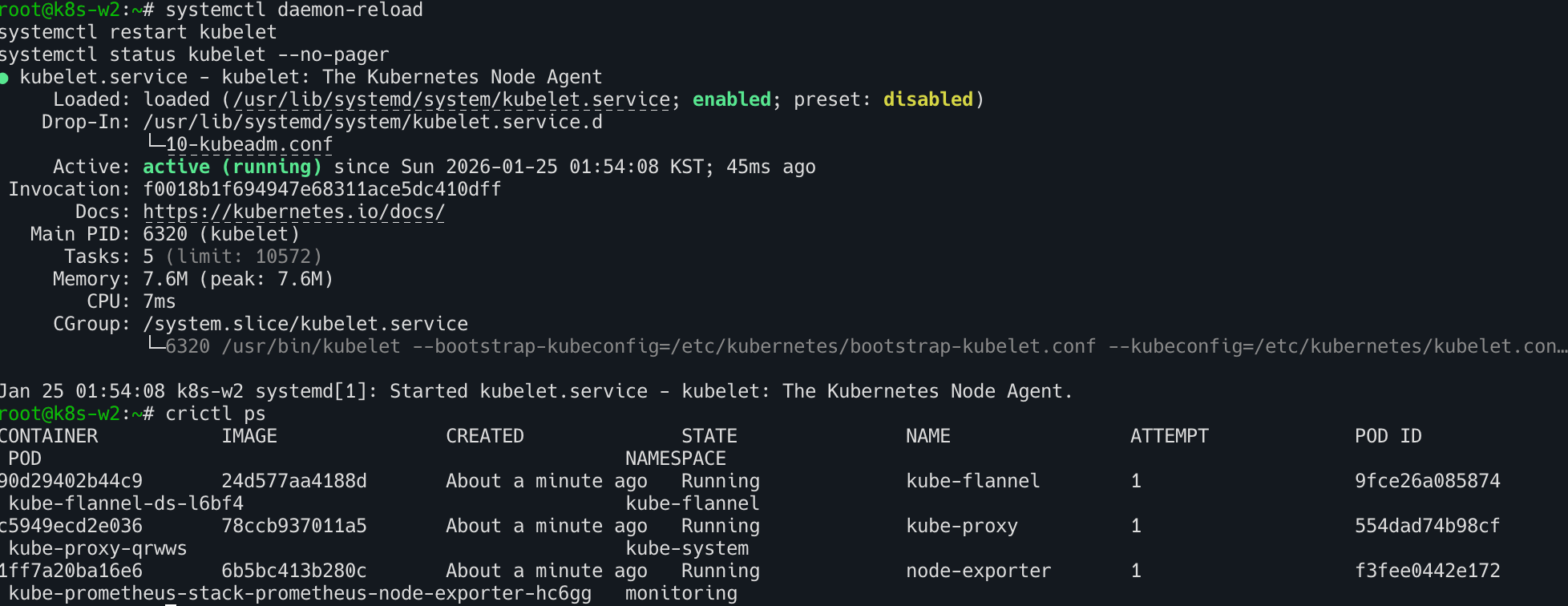
uncordon → 파드 배포해서 정상 동작 확인
vagrant ssh k8s-ctr1
1
2
kubectl uncordon k8s-w2
kubectl get node -owide

1
2
3
kubectl scale deployment webpod --replicas 1
kubectl scale deployment webpod --replicas 2
kubectl get pod -owide

k8s-w1 node drain 없이 업그레이드
- 작업 선택
- (방안2) 해당 노드에 별도 작업 시간 계획이 어렵거나, 거의 무중단으로 작업 해야 될 경우 : drain 없이 kubelet restart 수행
k8s-ctr1에서 해당 노드에 기동되고 있는 파드 정보 확인
- pv/pvc 를 사용하는 민감한 app 파드 존재
1
kubectl get pod -A -owide | grep k8s-w1

kubeadm upgrade node → kubelet/kubectl upgrade
vagrant ssh k8s-w1
repo 수정 : 기본 1.32 -> 1.33
1
2
3
4
5
6
7
8
9
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
1
dnf makecache
kubeadm 설치
1
dnf install -y --disableexcludes=kubernetes kubeadm-1.33.7-150500.1.1
노드 업그레이드 수행
1
kubeadm upgrade node
kubelet, kubectl Upgrade 설치
1
dnf install -y --disableexcludes=kubernetes kubelet-1.33.7-150500.1.1 kubectl-1.33.7-150500.1.1
1
2
3
4
# 재시작
systemctl daemon-reload
systemctl restart kubelet
systemctl status kubelet --no-pager
kubelet restart 후 crictl 컨테이너 상태 확인
- 별도 신규 생성되거나 하지 않았음을 확인 (생성시간 확인)
1
crictl ps
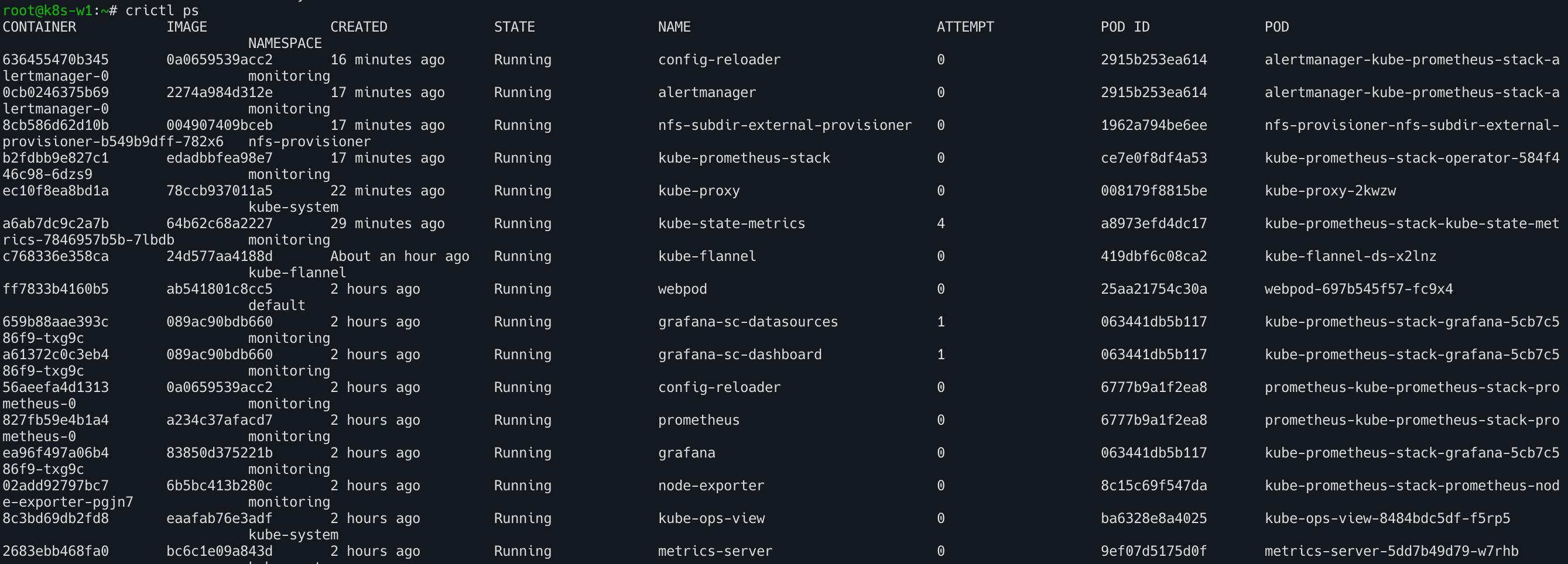
정상동작 확인
1
kubectl get node -owide
