[K8S Deploy Study by Gasida] - RKE2 - 4 etcd 스냅샷으로 클러스터 정보 백업
[K8S Deploy Study by Gasida] - RKE2 - 4 etcd 스냅샷으로 클러스터 정보 백업
ETCD 백업 및 복구 가이드
RKE2는 하드웨어 장애로 데이터가 유실되는 것을 대비해 강력하고 유연한 etcd 스냅샷 기능을 내장하고있다. 이번 과제에서는 로컬 저장소는 물론 S3 클라우드 저장소까지 지원하는 RKE2의 백업/복구 메커니즘을 정리한다.
1. 백업(Snapshot) 만들기
RKE2는 etcd 상태를 스냅샷 파일로 저장한다.
- 기본 저장 경로 아래와 같다
/var/lib/rancher/rke2/server/db/snapshots

1.1수동 저장 방법
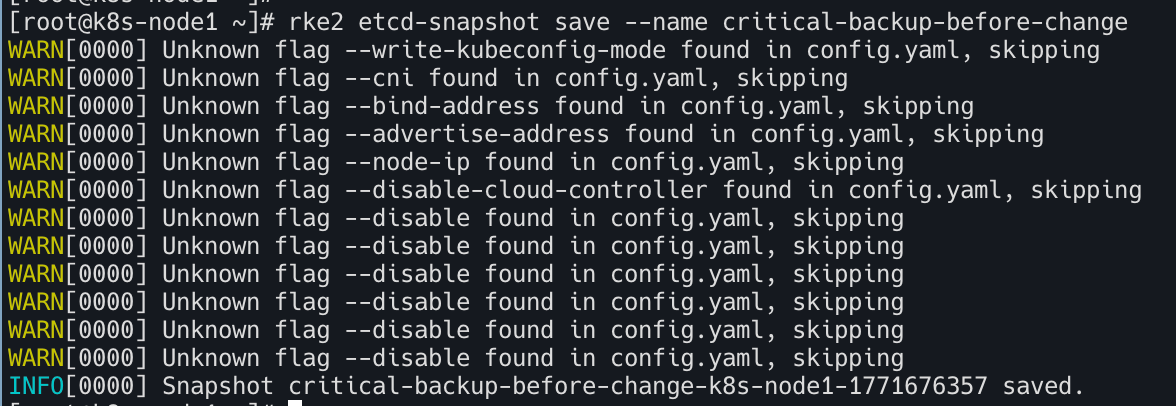
아래 명령어 실행하여 저장한다.
1
rke2 etcd-snapshot save --name critical-backup-before-change
1.2 자동 스냅샷(스케줄링)
운영 환경이라면 수동보다는 자동화가 필수이므로 config.yaml에 아래 설정을 추가해 주기적으로 백업을 수행한다.
etcd-snapshot-schedule-cron- 크론탭 형식으로 스케줄 설정
etcd-snapshot-retention- 보관할 스냅샷 개수 설정 (기본값 5개)
2. AWS S3에 RKE2 etcd 스냅샷 실제 백업하는 방법
로컬 저장 이외에도 RKE2는 S3 호환 저장소로 백업본을 바로 전송하는 기능을 제공한다.
주요 설정 필드
etcd-s3: S3 기능 활성화 여부etcd-s3-bucket: 저장할 버킷 이름etcd-s3-access-key/secret-key: 인증 정보etcd-s3-endpoint: AWS가 아닌 다른 S3 호환 서비스(Minio 등) 사용 시 필요
2.1 S3 버킷 및 IAM 준비
1
2
3
4
5
# 버전확인
aws --version
# 자격증명설정
aws configure
- 버킷 생성
1
2
3
4
aws s3api create-bucket \
--bucket hyeonjae-rke2-etcd-backup \
--region ap-northeast-2 \
--create-bucket-configuration LocationConstraint=ap-northeast-2
- public access 차단
1
2
3
aws s3api put-public-access-block \
--bucket hyeonjae-rke2-etcd-backup \
--public-access-block-configuration \ "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true"
- 버킷 생성 확인
1
aws s3 ls | grep hyeonjae-rke2-etcd-backup

2.2 config yaml 생성
- RKE2 설정 파일에 아래의 S3 백업 설정 추가
/etc/rancher/rke2/config.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# ----------------------------
# etcd 스냅샷 스케줄 설정
# ----------------------------
etcd-snapshot-schedule-cron: "*/3 * * * *" # 3분마다 자동 스냅샷
etcd-snapshot-retention: 5 # S3에 보관할 최근 스냅샷 수
# ----------------------------
# S3 백업 설정
# ----------------------------
etcd-s3: true
etcd-s3-bucket: hyeonjae-rke2-etcd-backup # 생성한 S3 버킷 이름
etcd-s3-region: ap-northeast-2 # 서울 리전
etcd-s3-folder: snapshots # 버킷 내 저장 경로 (없으면 루트에 저장)
# IAM 자격증명 방식 선택 (둘 중 하나만 사용)
# ① EC2 IAM Role 사용 시 (권장) → 아래 두 줄 삭제 또는 주석 처리
# ② IAM User Access Key 사용 시 → 아래 주석 해제 후 값 입력
etcd-s3-access-key: YOUR_ACCESS_KEY_ID
etcd-s3-secret-key: YOUR_SECRET_ACCESS_KEY
2.3 RKE2 재시작으로 설정 적용
1
systemctl restart rke2-server
2.4 수동으로 즉시 S3 백업 실행
1
2
3
4
5
rke2 etcd-snapshot save \
--etcd-s3 \
--etcd-s3-bucket hyeonjae-rke2-etcd-backup \
--etcd-s3-region ap-northeast-2 \
--etcd-s3-folder rke2/snapshots
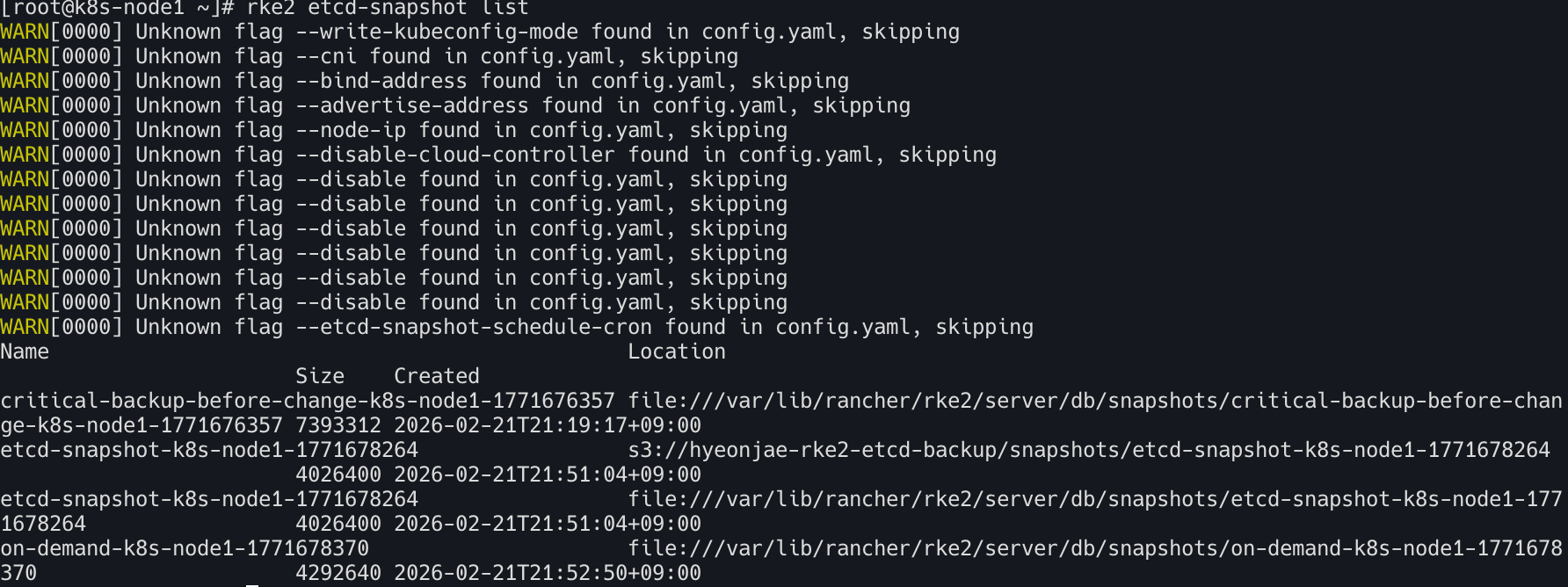
3. 스냅샷 목록 확인
아래 명령어로 스냅샷 목록을 확인
1
rke2 etcd-snapshot list

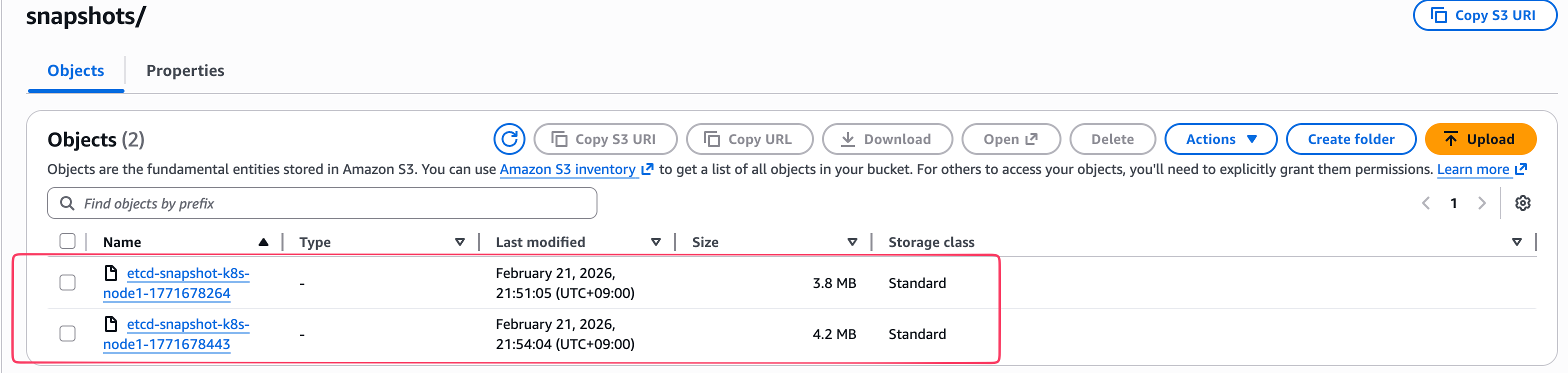
- aws s3 웹 콘솔에서 확인
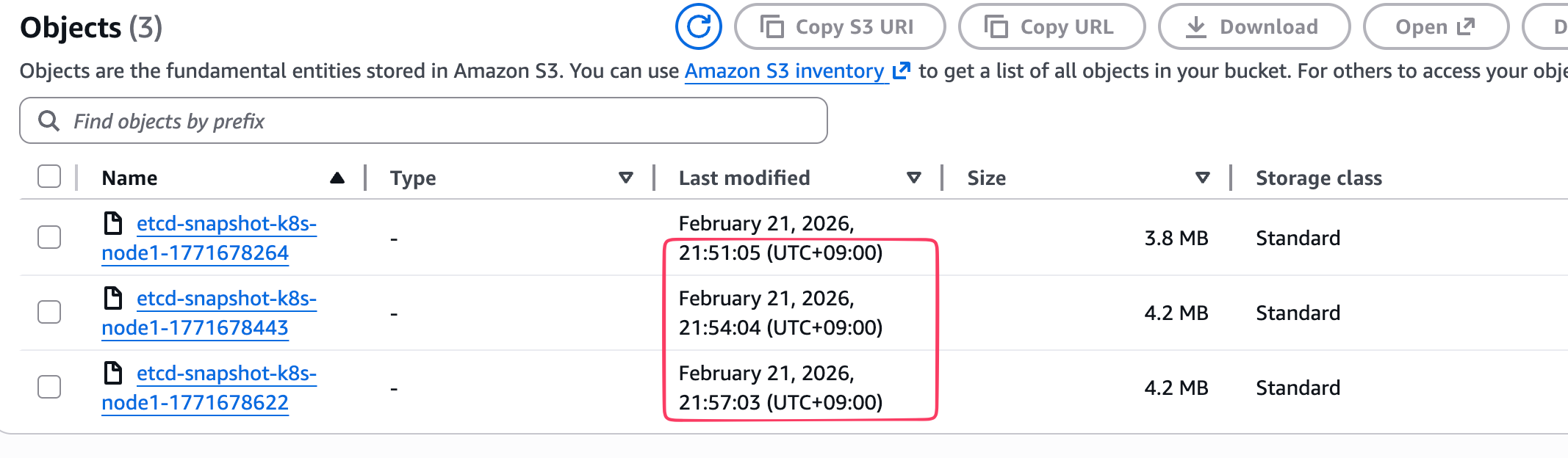
- 크론탭 설정대로 3분마다 백업되었는지 확인
3. 클러스터 복구하기 (Restore)
장애가 발생하여 백업본에서 복구해야 할 때 가장 주의할 점은 모든 노드의 RKE2 서비스를 중단해야 한다는 것이다.
복구 프로세스 (3단계)
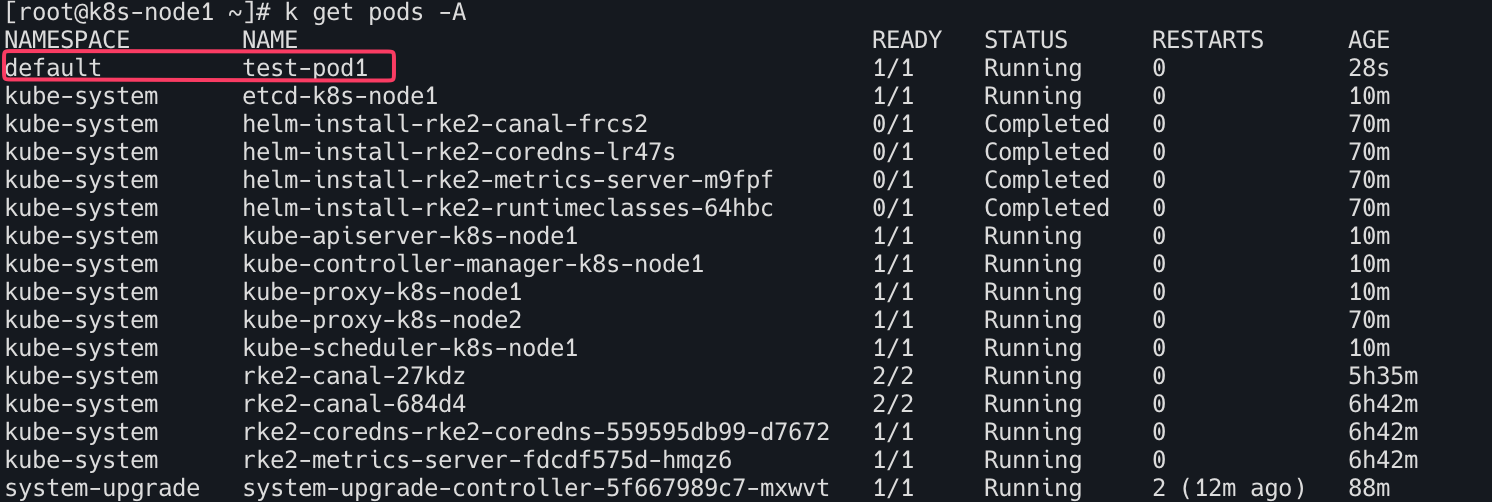
- 테스트를 위해
test-pod1(nginx) 기동
- 아래 명령어로 aws S3 버킷에 백업 대상을 확인
1
2
3
4
5
rke2 etcd-snapshot list \
--etcd-s3 \
--etcd-s3-bucket hyeonjae-rke2-etcd-backup \
--etcd-s3-region ap-northeast-2 \
--etcd-s3-folder snapshots
- 백업대상 이름 메모
etcd-snapshot-k8s-node1-1771680423

- 테스트 파드(
test-pod1) 삭제
- 서비스 중단
- 서버 노드에서 RKE2 서비스를 중단
1
systemctl stop rke2-server
- 첫번째 서버 노드에서만 해당 스냅샷 이름으로 복구명령을 실행
1
2
3
4
5
6
7
rke2 server \
--cluster-reset \
--cluster-reset-restore-path=etcd-snapshot-k8s-node1-1771680423 \
--etcd-s3 \
--etcd-s3-bucket hyeonjae-rke2-etcd-backup \
--etcd-s3-region ap-northeast-2 \
--etcd-s3-folder snapshots
ERRO로 표시되지만 실제 오류가 아니라 복원 완료 후 정상 종료 신호이다.

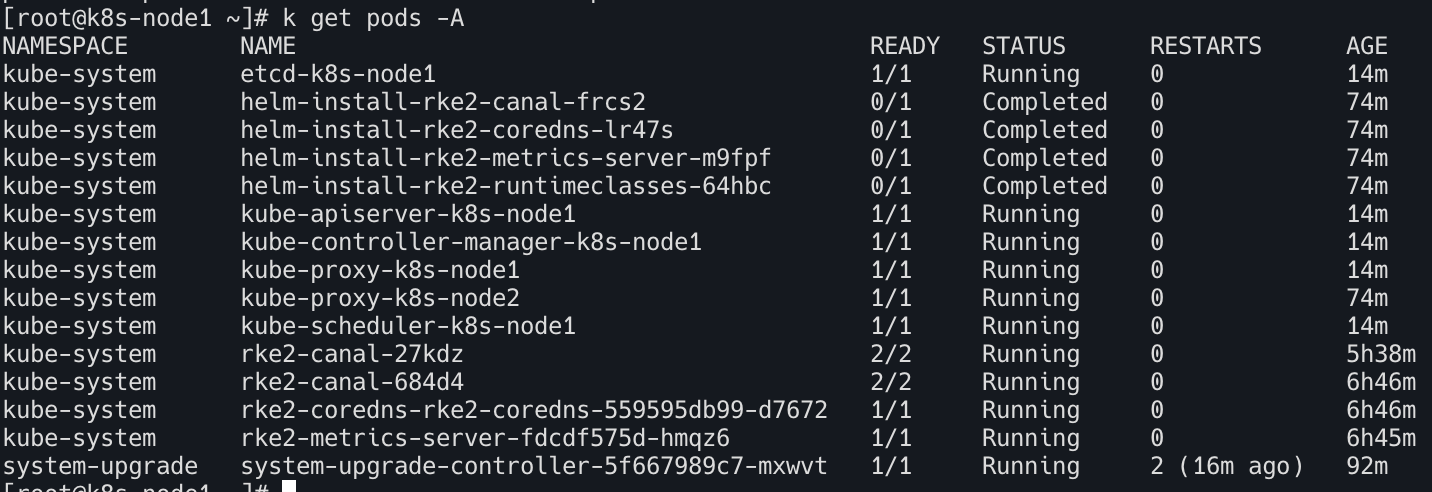
서비스 재시작 : 복구 명령이 성공하면 다시 서비스를 시작한다
1
systemctl start rke2-server
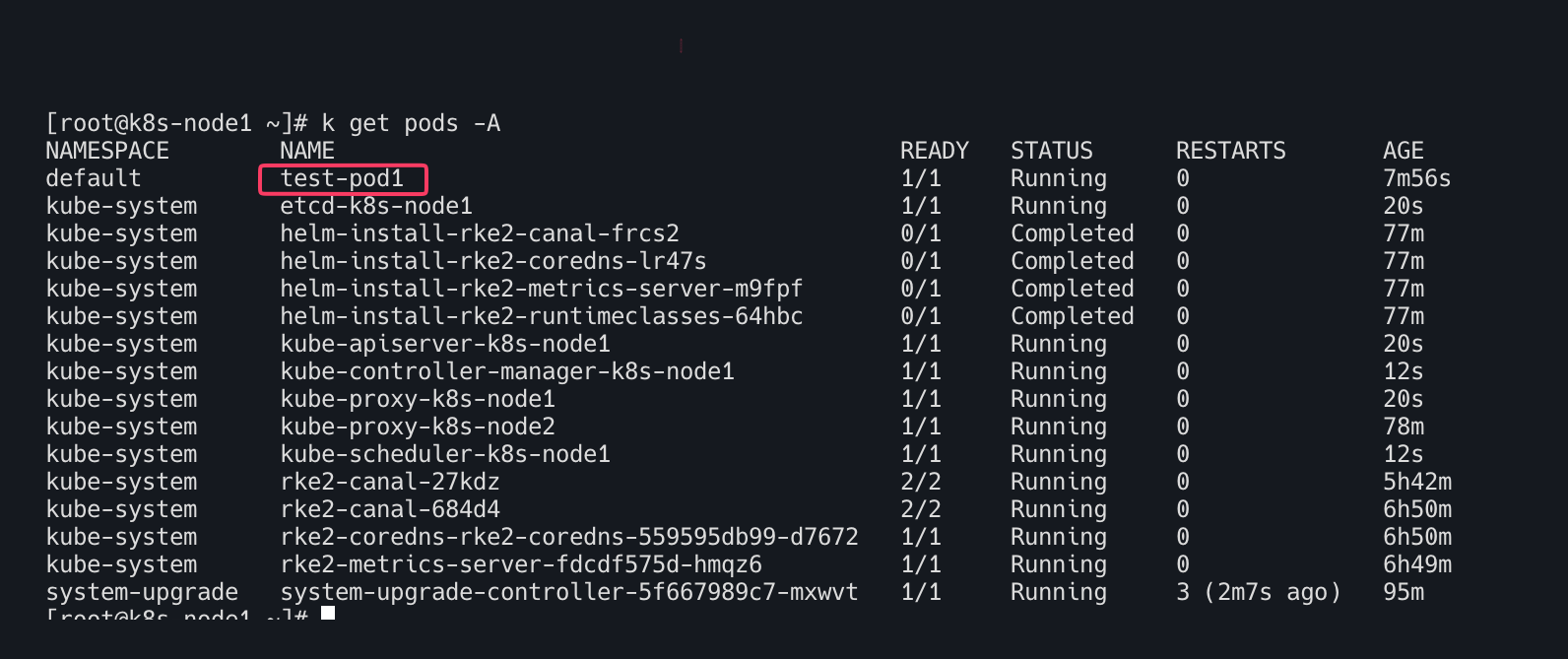
- 파드 상태 확인! :
test-pod1복원 완료!
- 멤버상태 확인
1
2
3
4
5
6
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/var/lib/rancher/rke2/server/tls/etcd/server-ca.crt \
--cert=/var/lib/rancher/rke2/server/tls/etcd/client.crt \
--key=/var/lib/rancher/rke2/server/tls/etcd/client.key \
member list

- 헬스 체크
1
2
3
4
5
6
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/var/lib/rancher/rke2/server/tls/etcd/server-ca.crt \
--cert=/var/lib/rancher/rke2/server/tls/etcd/client.crt \
--key=/var/lib/rancher/rke2/server/tls/etcd/client.key \
endpoint health

- ETCD 복원기록 로그 확인
1
journalctl -u rke2-server --no-pager | grep -i "snapshot\|restore\|reset"
- 주의사항
| 항목 | 내용 |
|---|---|
| 다중 서버 환경 | 복원은 첫 번째 서버 노드에서만 실행하며 나머지는 복원 이후에 재시작 |
| 토큰 | 새 호스트로 복원 시 원본 서버의 /var/lib/rancher/rke2/server/token 필요 |
| reset-flag | 복원 후 /var/lib/rancher/rke2/server/db/reset-flag 파일이 생성되며 정상 시작 시 자동 삭제 |
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.