[Cilium Study 1기 by Gasida] - Cilium Migration
기존 쿠버네티스 네트워킹의 문제점
Cilium은 모든 CNI 관련 작업을 처리 하고 ingress controller,Gateway API 및 기타 모든 기능을 구현한다. 하지만 일반적인 서비스 라우팅과 로드 밸런싱은 kube-proxy에게 위임한다. 하지만 이 역시도 Cilium을 사용하여 kube-proxy를 대체하도록 구성할 수도있다. 그렇다면 궁극적으로 kube-proxy를 대체하는 이유는 무엇인가? Kube-proxy는 트래픽을 분산 시키기한 IP Tables은 서비스가 늘어나는 동적인 쿠버네티스 환경에는 적합 하지 않다. 파드의 동적인 변화가 일어 날 때마다 전체 재구성이 트리거 될 수 있다. 즉 서비스를 하나 더 추가하거나 변경 할 때마다 IP Tables 룰을 다시 만들 어야 할 수도 있다.
하지만 Cilium의 경우 순차적으로 처리하는 IP Tables과는 다르게 해시테이블을 사용한다. 결과를 검색할 때 해시테이블을 사용하므로 훨씬 효율적이다. 즉 서비스 수가 늘어나도 처리 시간이 선형적으로 늘어나지 않는다. 따라서 증가하는 서비스에도 더 낮은 지연시간, 더 높은 확장성, 더 효율적인 로드 밸런싱 및 나은 옵저버빌리티, 디버깅을 갖추게 될 것이다.
쿠버네티스 클러스터를 실리움으로 마이그레이션하기
Cilium은 flannel과 같은 다른 CNI로부터 마이그레이션이 가능하다. 기존 트래픽 / 운영 클러스터의 중단 및 재구축 할 필요 없이 노드 별로 마이그레이션이 가능하다. 이 예제에서는 Cilium을 사용한 마이그레이션 작동 방식을 설명하고 있다.
Background
마이그레이션을 진행할 경우 일반적으로 Cilium cni를 포인팅 하도록 /etc/cni/net.d를 재구성하는데 이미 존재하는 파드는 여전히 기존의 CNI 설정값을 따르고 있다. 마이그레이션을 완료하기 위해서는 기존의 CNI로 구성된 클러스터드의 모든 파드를 새 CNI로 재구성하여야 한다.
한가지 단순한 방법으로는 모든 노드를 새로운 CNI로 재구성한 다음 클러스터의 각 노드를 점진적으로 다시 시작하여 노드가 다시 시작될 때 모든 파드가 새로운 CNI에 포함되도록 하는 것이다.
하지만 이러한 방법은 클러스터 연결이 중단되는 단점이 있으며 마이그레이션 되지않은 노드와 마이그레이션이 완료된 노드는 서로 고립 상태이며 파드는 마이그레이션이 완료 될때가지 서로 통신을 할 수가 없다.
듀얼 오버레이를 통한 마이그레이션
위와 같은 문제를 해결하기 위해 Cilium은 클러스터 전체에 두개의 별도 오버레이가 설정되는 하이브리드 모드를 지원한다. 특정 노드의 파드는 하나의 CNI에만 연결 될 수 있지만 마이그레이션이 진행되는 동안 Cilium 파드와 그렇지 않은 파드 모두 접근 할 수 있다.
이번 문서에서는 배포된 두개의 CNI간의 무중단 마이그레이션 모델에대해 논의하고자한다. 이러한 이점은 당연히 노드와 워크로드의 다운타임을 감소 시킬 수 있으며 마이그레이션이 진행되는 동안 각각의 CNI에서 워크로드가 원할 하게 통신 할 수 있도록 보장할 수 있는 이점이 있다.
요구사항 및 제한사항
Live Migration에서 필요한 것
- Cilium에서 사용 할 수 있는 새로운 CIDR
- 클러스터 풀 IPAM 모드 사용
- 프로토콜 또는 포트 중 하나의 고유한 오버레이
- Flannel, Calico 또는 AWS-CNI와 같은 Linux 라우팅 스택을 사용하는 기존 네트워크 플러그인
Cilium 마이그레이션에서 테스트되지 않은 항목
- BGP 기반 라우팅
- IP 패밀리 변경(예: IPv4에서 IPv6로)
- 체인 모드로 Cilium에서 마이그레이션
- 기존 NetworkPolicy 공급자
마이그레이션 중에는 Cilium의 NetworkPolicy 및 CiliumNetworkPolicy 적용이 비활성화 된다. 그렇지 않으면 Cilium이 아닌 파드에서 발생하는 트래픽이 사라질 수가 있다. 마이그레이션 과정이 완료되면 비활성화된 NetworkPolicy를 다시 활성화 할 수 있다. 기존 NetworkPolicy 프로바이더가 있는 경우 모든 NetworkPloicy를 일시적으로 삭제하는 것이 좋다.
클러스터풀 IPAM 할당기를 사용하여 Cilium을 설치하는 것이 좋다. (IP충돌 발생 방지)
마이그레이션 프로세스는 노드별 구성 기능을 활용 하여 Cilium CNI를 선택적으로 활성화 한다. 이를 통해 기존 워크로드를 중단하지 않고 Cilium을 제어된 방식으로 롤아웃 할 수 있다.
Cilium은 먼저 오버레이를 구축한다. 하지만 어떤 파드에도 CNI 네트워킹을 제공하지 않는 모드로 설치된다. 그 후에 개별 노드가 마이그레이션 된다.
- “secondary” 모드로 Cilium을 설치
- Cordon, drain 및 마이그레이션 후 각 노드 재부팅
- 기존의 네트워크 프로바이더 제거
마이그레이션 과정
준비사항
클러스터 생성을 위한 yaml 파일을 작성한다. 하나의 컨트롤 플레인과 4개의 워커노드를 생성한다. (기본적으로 Calico CNI가 설치되어있다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ cat <<EOF > kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
# nodepinger
- containerPort: 32042
hostPort: 32042
# goldpinger
- containerPort: 32043
hostPort: 32043
- role: worker
- role: worker
- role: worker
- role: worker
networking:
disableDefaultCNI: true
podSubnet: 192.168.0.0/16
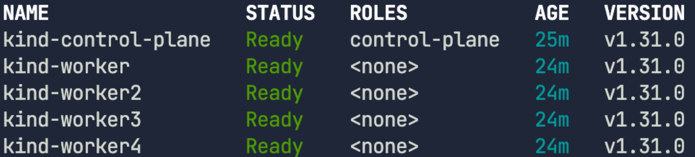
노드 상태를 확인 하자. 모든 노드가 Ready 상태로 정상 동작중이다.
1
kubectl get nodes
아래의 명령어로 Calico 데몬셋이 제대로 배포 되었는지 확인하자.
1
kubectl -n calico-system rollout status ds/calico-node
daemon set "calico-node" successfully rolled out 이라는 문구가 보이면 성공
또한 각 노드의 파드CIDR를 확인해보자.
1
kubectl get ipamblocks.crd.projectcalico.org \ -o jsonpath="{range .items[*]}{'podNetwork: '}{.spec.cidr}{'\t NodeIP: '}{.spec.affinity}{'\n'}{end}"

노드의 연결상태를 모니터링하기 위해 각 노드당 Goldpinger를 파드를 배포하자.
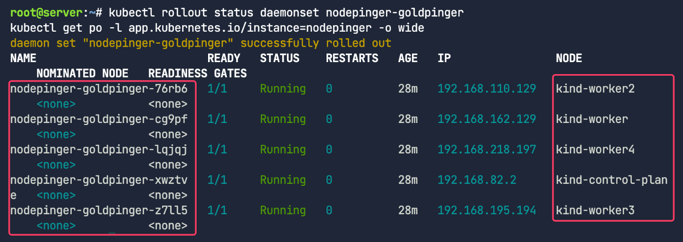
1
2
kubectl rollout status daemonset nodepinger-goldpinger
kubectl get po -l app.kubernetes.io/instance=nodepinger -o wide
현재 컨트롤플레인과 워커노드가 전부 연결 되어 있는 것을 시각적으로 확인 할 수 있다. (실습환경 기준) 
200상태를 응답하는지 확인해보자.
1
curl -s http://localhost:32042/check | jq
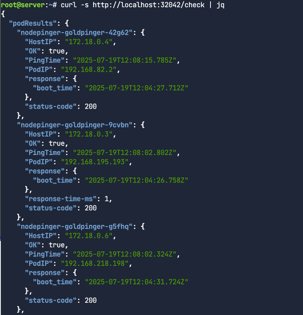
노드 헬스체크를 해보자. 5개의 노드(컨트롤1 + 워커4)가 모두 정상이다.

두번째 Goldpinger 배포
첫번째 Goldpinger 디플로이먼트는 실험적이며, 데몬셋을 사용하였으므로 우리가 마이그레이션을 위해 노드 드레인을 해도 삭제 되지 않는다. 차이를 비교하기위해 우리는 두번째 Goldpinger를 배포한다.
1
2
3
4
5
kubectl apply -f /tmp/goldpinger_deploy.yaml
kubectl rollout status deployment goldpinger
kubectl get po -l app=goldpinger -o wide
kubectl expose deployment goldpinger --type NodePort \
--overrides '{"spec":{"ports": [{"port":80,"protocol":"TCP","targetPort":8080,"nodePort":32043}]}}'
헬스체크
curl -s http://localhost:32043/check | jq
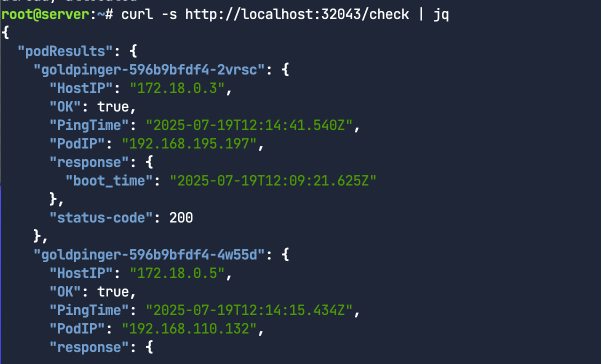
10개 모두 healthy한 것을 볼 수 있다.
curl -s http://localhost:32043/metrics | grep '^goldpinger_nodes_health_total'

파드 CIDR
가장 첫번째 단계는 새로운 파드를 위한 새로운 CIDR값을 결정하는 것이다. Calico는 아래와 같이 192.168.0.0/16을 기본적으로 사용한다. (flannel은 10.244.0.0/16) 충돌을 피하기 위해 우리는 10.244.0.0/16을 선택한다.(flannel일 경우 10.245.0.0/16으로 하자)
파드CIDR 확인 명령어
kubectl get installations.operator.tigera.io default \ -o jsonpath='{.spec.calicoNetwork.ipPools[*].cidr}{"\n"}'
프로토콜 인캡슐레이션
두번째 단계는 기존의 인캡슐레이션 포트와 다른 포트번호를 선택하거나 다른 프로토콜을 선택한다.
- Calico는 VXLANCrossSubnet 프로토콜을 사용하며 8472번 포트가 기본값이다. 우리는 충돌을 피하기 위해서 8473번 포트를 사용한다.
프로토콜 확인 명령어
kubectl get installations.operator.tigera.io default \ -o jsonpath='{.spec.calicoNetwork.ipPools[*].encapsulation}{"\n"}'
마이그레이션을 위한 Cilium Values
Cilium Helm 설정 파일을 아래와 같이 작성한다. (values-migration.yaml)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
## values-migration.yaml
operator:
unmanagedPodWatcher:
restart: false
tunnelPort: 8473
cni:
customConf: true
uninstall: false
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList: ["10.244.0.0/16"]
policyEnforcementMode: "never"
bpf:
hostLegacyRouting: true
Operator 설정
Cilium이 관리하지 않는 파드가 재시작되는 것을 막기 위한 오퍼레이터이다. (우리는 Cilium이 관리하지 않는 파드에 간섭하는 것을 원치않는다.)
1
2
3
operator:
unmanagedPodWatcher:
restart: false
VXLAN 설정
Cilium VXLAN과 Calico VXLAN 충돌을 막기위해 포트번호를 변경한다. (기본 8472)
1
tunnelPort: 8473
CNI 설정
customConf : true- CNI구성을 일시적으로 패스한다. 이는 Cilium이 즉시 작업을 처리하는 것을 방지하기 위함이다.
uninstall: false- false를 사용하면 Cilium이 Calico의 CNI 구성파일과 플러그인 바이너리를 제거하지 못하므로 임시 마이그레이션 상태가 허용된다.
1
2
3
cni:
customConf: true
uninstall: false
IPAM 설정
라이브 마이그레이션은 Cluster Pool IPAM 모드를 사용할 필요가있으며 파드CIDR은 Calico의 CIDR값과 구별될 필요가 있다.
1
2
3
4
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList: ["10.244.0.0/16"]
네트워크정책 설정
마이그레이션이 완료 될 때까지 네트워크정책을 비활성화 한다. 마이그레이션 후에는 네트워크 정책이 적용된다.
1
policyEnforcementMode: "never"
BPF 구성
호스트 스택을 통해 트래픽을 라우팅하여 마이그레이션 중 연결을 제공한다. 마이그레이션 도중 Calico 관리 파드와 Cilium 관리파드의 연결성을 확인한다.
1
2
bpf:
hostLegacyRouting: true
Cilium Helm Values 생성
cilium-cli를 사용하면 자동으로 클러스터 플랫폼을 감지하여 Helm values를 생성해 준다.
1
cilium install \ --helm-values values-migration.yaml \ --dry-run-helm-values > values-initial.yaml
- 위에서 생성한
values-migration.yaml사용 helm-auto-gen-values플래그를 사용하여 누락된 값을 자동으로 채움values-initial.yaml로 새로운 Helm Values 파일 생성
기본적으로 values-migration.yaml의 값들로 채우며 아래와 같은 값은 Cilium에 의해 자동으로 생성되어 values-initial.yaml을 채운다.
operator.replicascluster.idandcluster.namekubeProxyReplacement- the
serviceAccountssection encryption.nodeEncryption
Calico가 Cilium interfaces를 사용하지 못하도록 방지
노드에 Cilium을 설치할 때 Cilium은 cilium_host 라는 새로운 네트워크 인터페이스를 생성할 것이다. 만약 Calico가 cilium_host를 기본 네트워크 인터페이스로 사용한다면 당연 Calico 노드 라우팅은 실패할 것이다. 이러한 이유로 우리는 Calico가 cilium_host인터페이스를 무시하도록 해줘야한다.
단순하게, firstFound: false 와 kubernetes: NodeInternalIP 를 설정해주면 끝이다. 이러면 Calico는 노드 internalIP를 메인 인터페이스로 사용할 것이다.
패치전 확인
1
2
kubectl get installations.operator.tigera.io default \
-o jsonpath='{.spec.calicoNetwork.nodeAddressAutodetectionV4}{"\n"}'

patch 명령
1
kubectl patch installations.operator.tigera.io default --type=merge \ --patch '{"spec": {"calicoNetwork": {"nodeAddressAutodetectionV4": {"firstFound": false, "kubernetes": "NodeInternalIP"}}}}'
패치 결과 확인
1
2
kubectl get installations.operator.tigera.io default \
-o jsonpath='{.spec.calicoNetwork.nodeAddressAutodetectionV4}{"\n"}'

Cilium 설치
helm을 사용하여 cilium을 설치한다.
1
2
helm repo add cilium https://helm.cilium.io/
helm upgrade --install --namespace kube-system cilium cilium/cilium \ --values values-initial.yaml
cilium status --wait 으로 상태를 확인해보자. Cilium, Operator, Envoy DaemonSet 전부 OK이다. 마이그레이션이 아직 끝나지 않았으므로 Cilium이 관리하는 파드는 아래와 같이 0인것을 확인 할 수 있다.
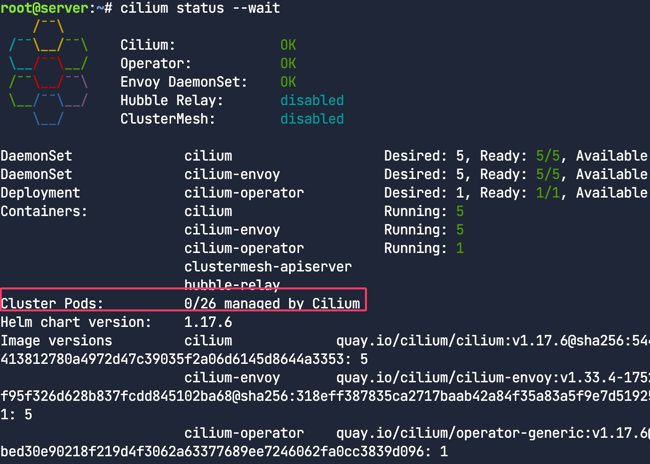
아래 docker 명령어로 워커노드에 진입해보면 /etc/cni/net.d/ 경로에 calico만 존재한다. Cilium은 모든 노드에 설치 되었고 노드 간에 오버레이가 설정되었지만 아직 노드의 Pod를 관리 할 수 있도록 설정해주지 않았다. 따라서 Kubelet은 아직 Cilium을 사용 할 수 없다.
1
docker exec kind-worker ls /etc/cni/net.d/

CiliumNodeConfig
Cilium 표준 설치에는 각 노드에 설치되는 Cilium 에이전트는 ConfigMap 리소스인 cilium-config에 관리되며 모두 같은 구성값을 가진다. 그러나, 이번 마이그레이션은 한번에 하나의 노드씩만 점진적으로 진행할 것이다. 그러기 위해서는 CiliumNodeConfg 리소스 타입(CRD - Cilium 1.13에서 추가됨) 을 사용 할 것인데 이는 각 노드별로Cilium 에이전트를 구성 할 수 있도록 지원한다.
아래와 같이 ciliumnodeconfig.yaml 을 작성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
apiVersion: cilium.io/v2
kind: CiliumNodeConfig
metadata:
namespace: kube-system
name: cilium-default
spec:
nodeSelector:
matchLabels:
io.cilium.migration/cilium-default: "true"
defaults:
write-cni-conf-when-ready: /host/etc/cni/net.d/05-cilium.conflist
custom-cni-conf: "false"
cni-chaining-mode: "none"
cni-exclusive: "true"
ciliumnodeconfig 파일 적용
1
kubectl apply --server-side -f ciliumnodeconfig.yaml
라벨 체크
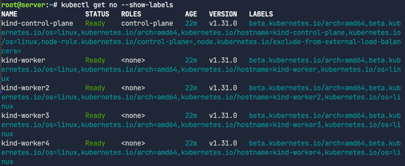
1
kubectl get no --show-labels
아직은 io.cilium.migration/cilium-default: "true" 에 매칭되는 라벨이 없다. 아직 실제로 어떤 노드에도 적용된 상황은 아니기 때문이다.
Migration
Cordon and Drain the Node
엔드유저가 영향을 받지 안혿록 마이그레이션 프로세스 초기에 노드를 격리하는 것을 추천한다. 노드를 봉쇄하면 새로운 파드가 해당 노드에 예약 되는 것을 방지 할 수 있다.
노드를 드레이닝 할 경우 실행중인 모든 파드가 노드에서 정상적으로 제거된다. 이를 통해 파드가 갑자기 종료되는 것을 방지하고 해당 파드의 워크로드가 다른 사용 가능한 노드에서 정상적으로 처리 될 수 있도록 한다.
kind-worker 노드를 cordon시키자.
1
2
NODE="kind-worker"
kubectl cordon $NODE
kubectl drain $NODE --ignore-daemonsets 로 노드를 드레이닝한다. 노드를 드레이닝 할 경우 해당 노드는 자동으로 격리된다.
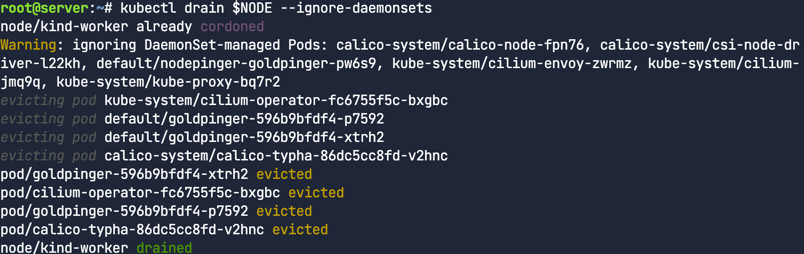
드레이닝 된 노드에서 실행중인 파드가 없는지 확인한다. 아래 사진의 경우 하나의 파드가 남아있는데 이는 데몬셋의 일부이기 때문이다.
1
kubectl get pods -o wide --field-selector spec.nodeName=$NODE

여전히 5개의 파드를 인식하는지 확인
1
curl -s http://localhost:32042/metrics | grep '^goldpinger_nodes_health_total'

라벨 지정 및 재시작
노드에 레이블을 지정하면 CiliumNodeConfig 가 노드에 적용된다.
1
kubectl label node $NODE --overwrite "io.cilium.migration/cilium-default=true"
노드의 Cilium을 재시작한다. 이것이 트리거가 되어 CNI configuration file을 생성할 것이다.
1
2
kubectl -n kube-system delete pod --field-selector spec.nodeName=$NODE -l k8s-app=cilium
kubectl -n kube-system rollout status ds/cilium -w

이제 해당 노드에 진입해보자. 아까와 다르게 05-cilium.conflist 가 생성되었다. 또한 10-calico.conflist.cilium_bak 으로 리네이밍된 것을 확인 할 수 있다.(백업 파일 생성) 이제 해당 노드의 kubelet은 CNI 프로바이더로 Cilium을 사용 할 수 있다.
1
docker exec $NODE ls /etc/cni/net.d/

그럼 체크해보자.
1
kubectl get po -l app.kubernetes.io/instance=nodepinger \ --field-selector spec.nodeName=$NODE -o wide

아직 192.168.0.0/16 대역인 것을 확인할 수 있다.
아래 명령어로 파드 재시작하자.
kubectl delete po -l app.kubernetes.io/instance=nodepinger \ --field-selector spec.nodeName=$NODE
다시 체크해보자.
1
kubectl get po -l app.kubernetes.io/instance=nodepinger \ --field-selector spec.nodeName=$NODE -o wide
‼ 파드아이피가 바뀐것을 확인 할 수 있다. 이제 10.244.0.0/16IP 수신이 가능하다.

연결상태가 양호한지 다시 확인하자.
1
curl -s http://localhost:32042/metrics | grep '^goldpinger_nodes_health_total'

Cilium 검증
cilium cli로 확인해보자. 아래 사진처럼 Cilium으로 관리되는 파드가 0개에서 1개로 늘어난 것을 확인 할 수 있다.
1
cilium status --wait
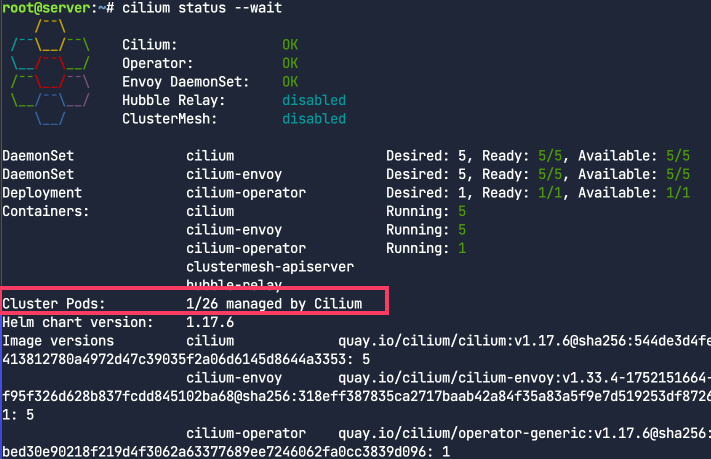
파드 CIDR를 확인 해보자.
1
kubectl get ciliumnode kind-worker \ -o jsonpath='{.spec.ipam.podCIDRs[0]}{"\n"}'

이제 노드를 다시 uncordon한다.
1
kubectl uncordon $NODE
goldpinger 파드 수를 다시 늘린다.
1
kubectl scale deployment goldpinger --replicas 15
새로운 파드에 할당된 IP를 확인한다
1
kubectl get po -l app=goldpinger --field-selector spec.nodeName=$NODE -o wide
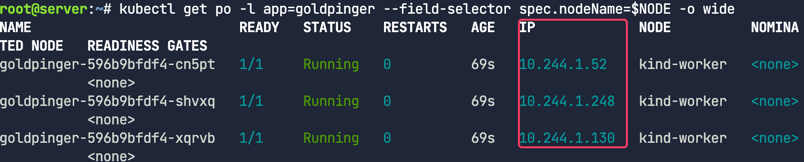
배포된 파드에서 모든 ping이 제대로 작동하는지 확인한다.
1
curl -s http://localhost:32043/metrics | grep '^goldpinger_nodes_health_total'

남아있는 워커노드에도 같은 작업 반복
1
2
3
4
5
6
7
for i in $(seq 2 4); do
node="kind-worker${i}"
echo "Migrating node ${node}"
kubectl drain $node --ignore-daemonsets
kubectl label node $node --overwrite "io.cilium.migration/cilium-default=true" kubectl -n kube-system delete pod --field-selector spec.nodeName=$node -l k8s-app=cilium
kubectl -n kube-system rollout status ds/cilium -w kubectl uncordon $node
done
- 결과 확인.
1
cilium status --wait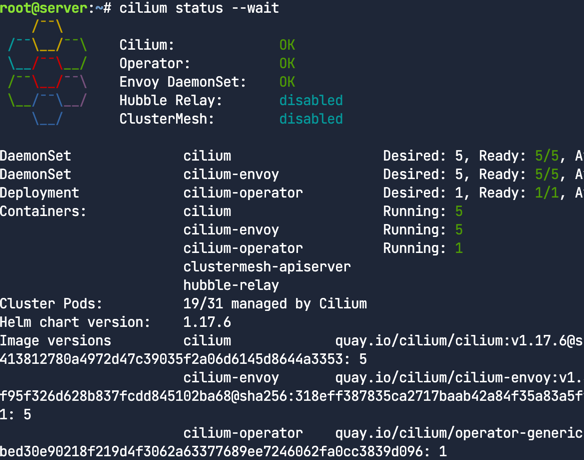
Nodeping DaemonSet 파드는 여전히 이전 파드 CIDR에 존재하므로 모두 다시 시작한다.
1
2
kubectl rollout restart daemonset nodepinger-goldpinger
kubectl rollout status daemonset nodepinger-goldpinger
1
kubectl get po -o wide
컨트롤 플레인을 제외한 워커노드의 파드들의 IP대역이 바뀐것을 확인할 수 있다. 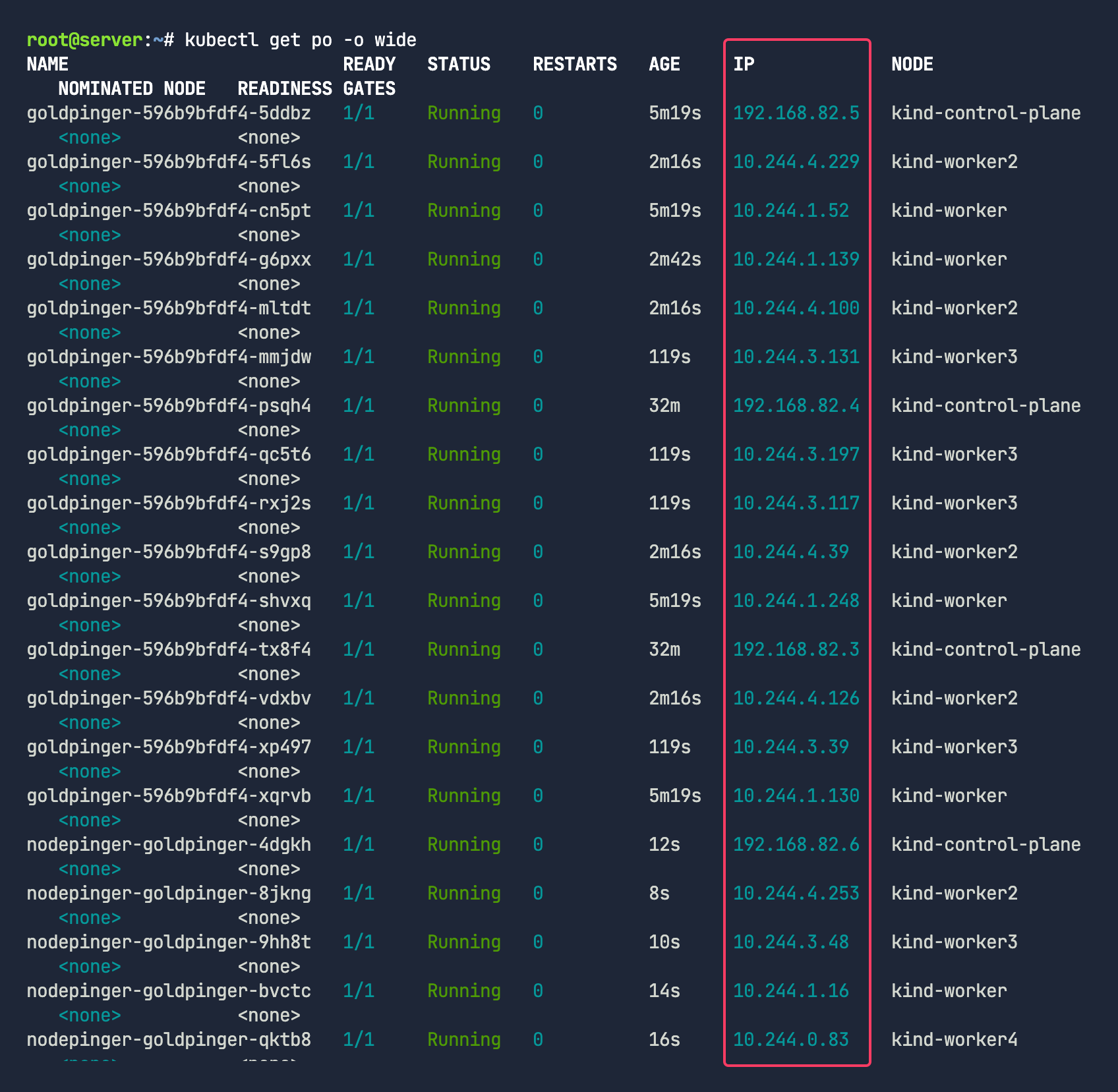
헬스체크
1
2
curl -s http://localhost:32042/metrics | grep '^goldpinger_nodes_health_total'
curl -s http://localhost:32043/metrics | grep '^goldpinger_nodes_health_total'

컨트롤 플레인에 대해서도 반복
1
2
3
4
NODE="kind-control-plane"
kubectl drain $NODE --ignore-daemonsets
kubectl label node $NODE --overwrite "io.cilium.migration/cilium-default=true" kubectl -n kube-system delete pod --field-selector spec.nodeName=$NODE -l k8s-app=cilium
kubectl -n kube-system rollout status ds/cilium -w kubectl uncordon $NODE
Nodepinger파드를 모두 재시작한다.
1
2
kubectl rollout restart daemonset nodepinger-goldpinger
kubectl rollout status daemonset nodepinger-goldpinger
모든 존재하고있는 모든 파드를 Cilium으로 마이그레이션을 완료하기 위하여 calico-system의 네임스페이스를 가진 csi-node-driver 데몬셋파드를 재시작한다.
1
2
kubectl rollout restart daemonset -n calico-system csi-node-driver
kubectl rollout status daemonset -n calico-system csi-node-driver
최종 상태를 확인하자.
1
cilium status --wait
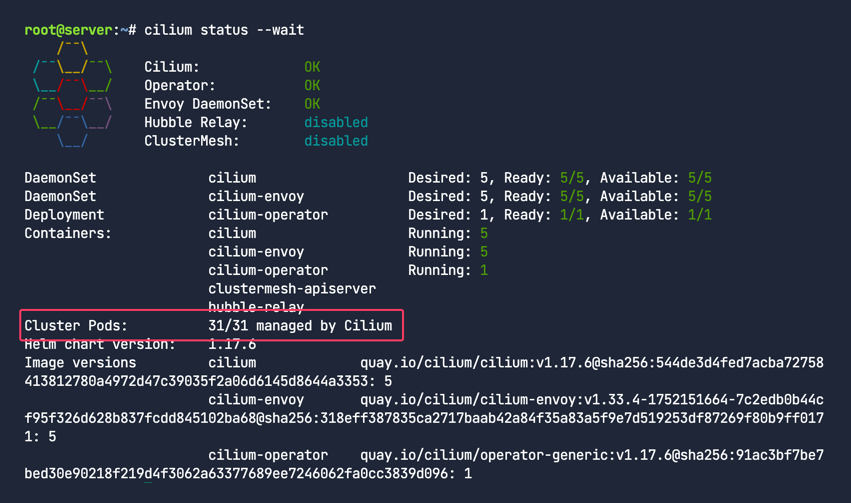
이로써 모든 파드들이 Cilium관리하에 들어왔다. 마이그레이션은 성공적이다.
클린 업
네트워크 정책을 지원하도록 Cilium 구성을 업데이트하고 이전 네트워크 플러그인을 제거한다. 몇가지 파라메터를 오버라이딩하는 Helm values 파일을 새롭게 생성하자.
Cilium이 정상화 되었으므로 Cilium 구성을 업데이트 하자.
1
2
3
4
5
6
cilium install \
--helm-values values-initial.yaml \
--helm-set operator.unmanagedPodWatcher.restart=true \
--helm-set cni.customConf=false \
--helm-set policyEnforcementMode=default \
--dry-run-helm-values > values-final.yaml
우리는 cilium-cli 사용하여 업데이트된 Helm config파일을 생성한다. 기존과 무엇이 다른지 확인해보자.
1
diff -u --color values-initial.yaml values-final.yaml
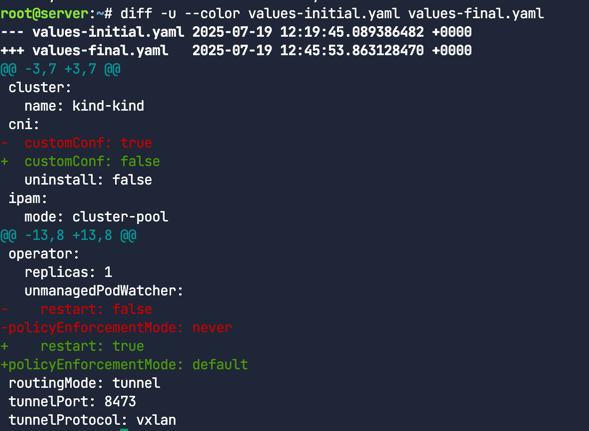
- 보는바와 같이 노드 구성 값을 disabling하며 Cilium CNI 구성파일을 작성한다.
- Cilium은 관리되지 않은 파드들을 재시작 할 수 있도록 설정
- NetworkPolicy를 활성화 한다.
이제 아래와 같이 적용하고 Cilium 데몬셋을 롤아웃 시키자.
1
2
3
4
5
helm upgrade --install \
--namespace kube-system cilium cilium/cilium \
--values values-final.yaml
kubectl -n kube-system rollout restart daemonset cilium
cilium status --wait
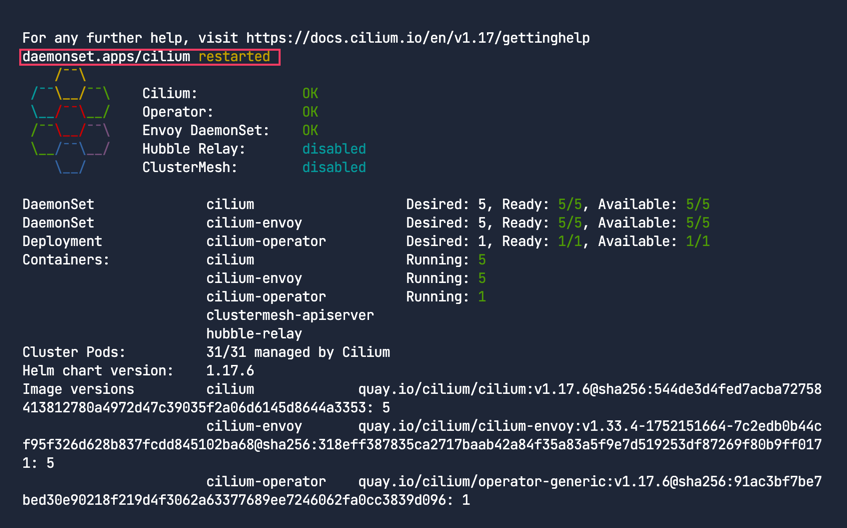
마지막으로 CiliumNodeConfig 리소스를 삭제한다.
1
kubectl delete -n kube-system ciliumnodeconfig cilium-default
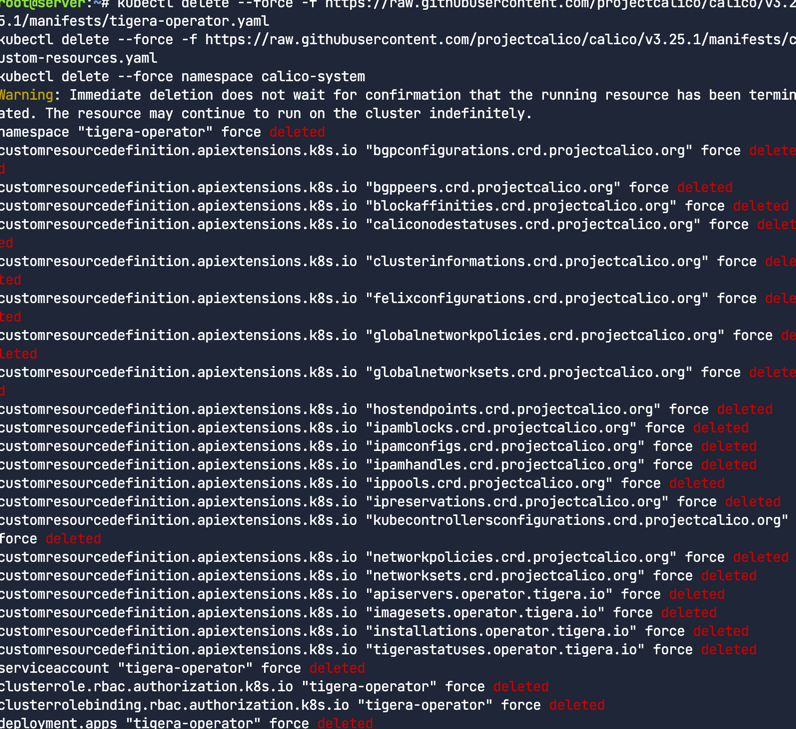
기존의 네트워크 플러그인을 삭제
1
2
3
kubectl delete --force -f https://raw.githubusercontent.com/projectcalico/calico/v3.25.1/manifests/tigera-operator.yaml
kubectl delete --force -f https://raw.githubusercontent.com/projectcalico/calico/v3.25.1/manifests/custom-resources.yaml
kubectl delete --force namespace calico-system
노드 재시작
워커노드를 재시작하자
1
2
3
4
5
6
7
for i in " " $(seq 2 4); do
node="kind-worker${i}"
echo "Restarting node ${node}"
docker restart $node
sleep 5 # wait for cilium to catch that the node is missing
kubectl -n kube-system rollout status ds/cilium -w
done
컨트롤 플레인을 재시작하자
1
2
3
docker restart kind-control-plane
sleep 5
kubectl -n kube-system rollout status ds/cilium -w
Cilium 상태확인
1
cilium status --wait
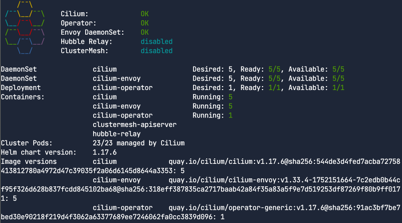 데몬셋과 Goldpinger 디플로이먼트를 확인해보자
데몬셋과 Goldpinger 디플로이먼트를 확인해보자
1
curl -s http://localhost:32042/metrics | grep '^goldpinger_nodes_health_total' curl -s http://localhost:32043/metrics | grep '^goldpinger_nodes_health_total'
컨트롤 플레인을 재시작 했기 때문에 다운 타임이 발생할 수 있다. (unhealthy) 
시간 간격을 좀 두고 확인해보자

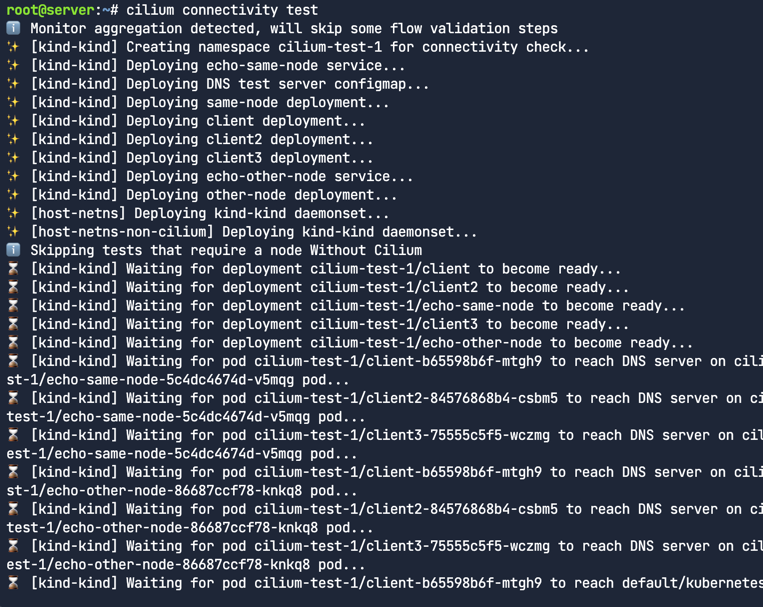
연결성(connectivity)를 확인하자.
1
cilium connectivity test